A/Bテストの数理 - 第3回:テストの基本的概念と結果の解釈方法について -
スケジュール
- 第1回 [読み物]:『人間の感覚のみでテスト結果を判定する事の難しさについて』:人間の感覚のみでは正しくテストの判定を行うのは困難である事を説明し,テストになぜ統計的手法が必要かを感じてもらう。
- 第2回 [読み物]:『「何をテストすべきか」意義のある仮説を立てるためのヒント』:何をテストするか,つまり改善可能性のある効果的な仮説を見いだす事は,テストの実施方法うんぬんより本質的な問題である(かつ非常に難しい)。意義のある仮説を立てるためのヒントをいくつか考える。
- 第3回 [数学]:『テストの基本的概念と結果の解釈方法について』:テストの基本的な数学的概念を説明し,またテスト結果をどのように解釈するのかを説明する。
- 第3回補足 [数学]:『仮説検定の概念を改めて考える』:テストの概念をもう少し丁寧に説明する。
- 第4回 [数学]:『実分野における9個のテストパターンについて』その1,その2:オンラインゲーム解析とキャンペーン事例に見る,テストにおける統計量の計算について説明する。
- 第5回 [数学]:『実際にテストを体感する』:いくつかのテスト事例に対し,サンプルデータを提供し実際に統計量の算出を行ってもらう。新シリーズ:「Treasure Data Analytics」の枠組み内で紹介することになりました。
(※ [読み物] は数学知識を前提としない内容で [数学] は数学知識をある程度前提としたおはなし。)
はじめに
第3回ではテストの概念および解釈の方法について説明する。はじめに統計学を強力にサポートする確率論の「大数の弱法則」「中心極限定理」を紹介する。次に背理法に基づくテストの概念を紹介する。
Ⅰ. 統計学の基本スタンスについて
第1回のコラムの続きから始めよう。コラムでは「僕たちは神ではないので答え(真の分布)を知ることはできない。よってその答えに対するヒント(サンプル)から答えを推定することしかできない。」と書いた。(「サンプル」は以後「標本」と呼ぶ。)
僕たちが手元に得られるデータというのは,たいていの場合が全体(母集団)の中の一部(標本)である事が多い。例えば労働調査データでは国民全員のデータでは無く,その中の10万人を独立ランダムにピックアップしたものである。
また,母集団の中からどのようなルール(分布)に従って標本が得られるのかもわからないことが多い。例えば(必ずしも平等でない)コイン投げでは,その母集団は {表, 裏} であることは知っていても表がどれくらいの確率で現れるのかはわからない。
世の中の多くの事象というのはこのように母集団や分布といったそれの本質的な部分を知ることはできず,そこから抽出される一部の標本の持つ(統計量と呼ばれる)情報からそれらを類推しないといけない。
統計学(特に推測統計学と呼ばれるが,ここでは統計と呼ぶことにする)というのは,得られている標本の統計量(標本平均や標本分散)をもとに全体(母集団)や真の分布をテスト(検定)したり推定したりする学問領域である。
Ⅱ. 現実と神の世界を結びつける架け橋:確率論
統計は,現在手元に得られている標本から理論上の真の分布や母集団の情報(誰も知り得ない言わば神の世界)を想像しようとするが,そのためには「現実」と「理論」を結びつけるための何かしらのサポートが不可欠である。この大きな隔たりを極限の世界において華麗に結びつけてくれるのが「大数の弱法則」と「中心極限定理」と呼ばれる,確率論より導かれる性質である。
が,平均
,分散
の独立同一な確率変数列であるとする。今,
と置いたとき,任意の ε > 0 に対して,
が成立する。
大数の弱法則を大まかに言えば,標本数 n を十分に大きくしていけばその標本平均は定数 μ(真の平均)に限りなく近づいていくということを表している。コイン投げの文脈では,試行回数が多ければ多いほど実験で表の出る確率は,真の確率,つまり真のコインの姿をより鮮明に浮かび上がらせる事ができることを示している。
期待値 μ, 分散 の独立同分布の確率変数列
の独立同分布の確率変数列  に対し、
に対し、
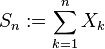
とすると、の標準化統計量
は平均 0, 分散 1 の正規分布 N(0, 1) に分布収束する:
 。
。
中心極限定理を大まかに言えば,標本数 n が十分に大きい状況では標本平均  の分布は近似的に平均
の分布は近似的に平均  , 分散
, 分散  の正規分布
の正規分布  に従う事を述べている。(また,
に従う事を述べている。(また, の分布は近似的に平均
の分布は近似的に平均  , 分散
, 分散  の正規分布
の正規分布  に従うとも言える。)
に従うとも言える。)
ではコイン投げを例に,大数の弱法則と中心極限定理の持たらす意味を考えてみることにしよう。今,平等なコインのコイン投げにおいて表の出る確率を実験によって求めてみる事にする。
※ コイン投げでは,i 回目のコイン投げにおいて表が出たときに1, 裏が出たときに0を取るような確率変数 を仮定すると,独立な変数列
の和
は表の出る回数を表していることになり,これを標本数 n で割った平均
は表が出る確率を表している事になる。この時
をベルヌーイ確率変数とよび,和
の分布は二項分布に従う。
大数の弱法則が意味するところは,コインを投げる回数を増やしていけば行くほど,実験から求めた表の出る確率は真の確率 1/2 に近づくことを示している。コインを n = 1,2,…,1000回独立に投げた場合の表の出る確率をグラフにしてみると,

のようになり,確かに n が大きくにつれて確率 1/2 に近くなっていく。Rにおけるサンプルコードはこちら。
標本数(試行回数) n を一定の値に固定し,毎回コインの表が出ると1, 裏が出ると 0 を標本として取る事にする。ここでは標本平均では無く標本の和,つまり表の出る回数 s を求める動作を 1 セットとして,これを数セット繰り返しヒストグラムを描くことで表の出る回数 s の分布を見てみることにする。下図は左から標本数を n = 10, 20, 1000としたときの分布を表している。標本数が大きいほど,表の出る回数の分布はこの定理より導かれる平均 n*0.5,分散 n*0.5*0.5 の正規分布を良く近似していることがわかる。(ここでセット回数は関心の中心では無い。ヒストグラムの様子を良く表すために n に応じて回数を増やしている)

また,パラメータ σ = 100 の指数分布においては,標本数 n が大きくなるほど,標本平均の分布がよく正規分布を近似している事がよくわかる。

Rでのサンプルコードはこちら。
標準正規分布
標準正規分布は平均 0, 分散 1の正規分布である。この確率密度関数のグラフは以下の図様に表される。縦軸は出やすさの度合い,横軸の値は標本値(標準正規分布における横軸の値をz-valueと呼ばれる。)を表している。縦軸が最大となる標本値はその平均 0 に一致し,そこを頂とする山を形成している。これは標準分布に従った標本を抽出していく場合には,平均値 0 周りを中心に多くの標本値が得られることを意味している。100個の標本値の様子をRで実験してみよう。
table関数によって頻度集計を行うと,ほとんどの標本値が区間 [-2, 2] 内に落ちていることがわかる。実際,95% の標本値が区間 [-1.96,1.96] に落ちることになる。逆に言えば標本値が ±1.96 より離れた標本が得られる確率は両側合わせてたった 5%でしかない。もしあなたがちょうど1回の標本を抽出してみたときに,±1.96 より離れた標本が得られたならば,そのあまりにも希少な出来事に目を疑うことだろう。

Ⅲ. テストの概念について
さて,テストの概念について説明できる準備が整った。ここまででわかっている事実を改めて並べて見よう。(以降で扱う標本は,独立かつ同一な分布から得られていると仮定する。)
- [大数の弱法則] 標本数が十分大きければ標本平均は真の平均に近づいていく。必要ならば真の平均の代替としてこの標本平均を用いて計算を行う事が可能である。
- [中心極限定理] 標本数が十分大きければ元の標本が従う分布が何であっても,標本平均の分布は近似的に正規分布 N(μ, σ^2/n) に従う。さらに標準化と呼ばれる変換を施すことによって得られる統計量 T は標準正規分布 N(0,1) に従う。
- [稀なケース] 標準正規分布においてz-valueが区間 [-1.96, 1.96] 内に収まらない確率は 5% でしかない。(ここで 2. における統計量 T と3. における z-value は同じである。)
もし実験から得た標本から求める統計量 T が計算可能ならば,Tは標準正規分布からの1つの標本であると考えることができる。
定義
「テスト(仮説検定:Hypothesis Testing または有意性検定:Significance Test)とは,母集団または真の分布について設定した仮説の妥当性の判断を,標本を元に計算する統計量を元に一定の確率水準で判定する事である。」
概念
A/Bテストの同型問題であるコイン投げの例では「コインAとコインBの表の出る確率は異なるはずだ」とういう仮説の下でテストを行う。今コインAの表の出る確率を p_a, コインBのそれを p_b とすれば,この仮説は数学的表現として「p_a ≠ p_b である」と表すことができる。しかし実際に設定する仮説は,その対となる「p_a = p_bである」の方になるので注意が必要である。(「p_a = p_bである」という仮説を帰無仮説,これに対立する「p_a ≠ p_bである」という仮説は対立仮説と呼ばれる。 )
これには以下の様な理由がある。(主に最初の方が重要)
テストは棄却を目的とした帰無仮説「p_a = p_bである」の元に検証が行われる。もしこの仮説が妥当では無い(完全否定とは意味合いが異なる)と判断できる場合は帰無仮説を棄却し,対立仮説「p_a ≠ p_bである」の方をより妥当として採択する。
テストでは「否定」という言葉は使わずに「棄却」という言葉を使用する。また帰無仮説の「帰無」とは「棄却することを前提に設定されているので,無に帰す」という意味合いが込められている。
帰無仮説を棄却するということの意味
(今後は区間 [-1.96,1.96] を「採択域」,採択域の外側を「棄却域」と呼ぶことにする。この言葉の意味はすぐに理解できるだろう。)
ではどのようにして帰無仮説を棄却するのだろうか?ここで標本分布の話を思い出して欲しい。帰無仮説の元では統計量 T は標準正規分布に従うが,その値が棄却域に入っているならばこのテストにおいては非常に稀な値を手にしてしまったことになる。
もし僕たちが真の分布を知っている神の立場であれば,この場合でも「稀なケースだったね」という話で済むだろうが,何せ僕たちは(仮定はおいているものの)真の分布を知らない。そのような立場からこの状況を判断するならば,「稀なケース」と考えるよりも「そもそも帰無仮説が正しくなかったのでは無いか」と考える方が妥当の様に思われる。
その考えのもと,T が棄却域に落ちるケースでは帰無仮説を棄却し,例えば「有意な差があると言える」と判断する。「有意」という言葉には「起こる確率が小さい場合には,それはめったに起こらないのでもしそれが起こったとすれば,それは偶然ではなく何か明白な意味が有ると考える方が妥当である」という意味合いが込められている。
ただ状況によっては棄却するか否かの厳しさ,つまり「妥当性の天秤」が異なってくることに注意が必要である。帰無仮説の元で稀なケースを観測する確率を α (ここではずっと α = 0.05 = 5%と置いてきた) とし,これを有意水準と呼ぶ。この有意水準を調整することによってこの妥当性の天秤を調整するのである。一般的に有意水準 α は 0.05 か 0.01 に設定される。後者はより起こりにくい確率を定義しているので,前者よりも帰無仮説を棄却しにくくなりより厳しいテストとなる。有意水準 0.01 の元では採択域は [-2.58, 2.58] と広くなるからだ。
第一種の誤り・第二種の誤り
ただ,本当に稀なケースに遭遇していた可能性もありうる。帰無仮説を誤って棄却してしまう(これを第一種の誤りと呼ぶ)可能性だ。
テストにおいて最終的に導かれる判断には第一種の誤りの可能性を常に含んでいるために,「有意な〜」や「〜であると言える」という控えめな表現を用いる。逆に採択域に収まるケースでは,帰無仮説を棄却することはできないので「このテストからは何もわからない」という判定をする。ここで,”帰無仮説を採択する”という判定を行い,「〜は同じであると言える」などと言ってはいけない。
∵ テストにおいては先ほど紹介した第一種の誤りの他に,第二種の誤りの可能性も内在している。第一種とは逆で,「偽である帰無仮説を採択してしまう誤り」である。第一種ではその誤りの確率は有意水準に等しく,故に制御可能な誤りである。一方,第二種の誤りの方は制御不可能な誤りであり,その確率は未知である。故に安易に帰無仮説を採択する行為は,確率未知の第二種の誤りを容認してしまうことになるので安易に帰無仮説を採択することはできない,故に「何も言えない」という判定にするのである。
問:『今年,新型かもしれないインフルエンザ  が流行の兆しを見せている。もし過去に類を見ないタイプであればすぐに新薬を開発して流行を食い止めなければ大変な事になる。そこで, が本当に新型かどうかを確認するために,患者の症状および血液検査の結果を,過去の似通ったインフルエンザ
が流行の兆しを見せている。もし過去に類を見ないタイプであればすぐに新薬を開発して流行を食い止めなければ大変な事になる。そこで, が本当に新型かどうかを確認するために,患者の症状および血液検査の結果を,過去の似通ったインフルエンザ  が流行した際に取っていた結果と比較し,結果に差があるかどうかをテストすることにした。帰無仮説を「インフルエンザ と は同じである」とした時,第一種の誤りおよび第二種の誤りが何であるかを指摘し,それがもたらす影響を考え,どちらが重大な過ちであるかを考えよ。』
が流行した際に取っていた結果と比較し,結果に差があるかどうかをテストすることにした。帰無仮説を「インフルエンザ と は同じである」とした時,第一種の誤りおよび第二種の誤りが何であるかを指摘し,それがもたらす影響を考え,どちらが重大な過ちであるかを考えよ。』
答:
- 第一種の誤り:
- 第二種の誤り:
Ⅳ. A/Bテストにおける統計量の計算方法について
(※ 統計量の計算とそれの従う分布について,興味の無い方は種々の公式だけ覚えて置けば良いので読み飛ばしてもらっても構わない。)
A/Bテストの同型問題のコイン投げで考える。コインAを n_a 回投げて表の出た回数を y_a,コインBを投げて表の出た回数を y_b と置き,ここでは標本数 n_a, n_b が十分大きいとする。また,それぞれの標本平均を  および
および  と置く。帰無仮説を「p_a = p_b (= p)である」とおく。これは2つの分布の差「p_a - p_b が 0 である」とも書ける。ところで正規分布には以下の様な良好な性質を持っている。
と置く。帰無仮説を「p_a = p_b (= p)である」とおく。これは2つの分布の差「p_a - p_b が 0 である」とも書ける。ところで正規分布には以下の様な良好な性質を持っている。
に従う。帰無仮説の元で共通の確率 p を標本推定値
で置き換えることにすると,標準化した統計量 T は
となり,この時 T は近似的に標準正規分布に従う。
サンプル数とサンプル数の偏りの影響
第1回では,「テストの判定が(人間の感覚的に)標本数の大きさや,標本数で偏りで信念が揺らぐ」傾向にあるという事に触れた。これは先ほど求めた統計量 T が標本数 n_a および n_b の値に依存していることより正しくそれが言える。今回のA/Bテストで導かれた統計量は n_a や n_b が大きくなれば分母が小さくなり,統計量 T としては値が大きくなる傾向にある。これは区間 [-1.96, 1.96] からどんどん遠ざかっていく事を意味し,「とっても稀なケース」としてより確信度高く帰無仮説を棄却できる。
p-値
ところで,この「確信度」というのは「p-値」と呼ばれており,帰無仮説の下で実際にデータから計算された統計量よりも極端な(大きな)統計量が観測される確率である。標準正規分布に従う統計量が T=1.96 の時,有意水準 0.05 の元では p-値は0.025である(両側を併せると有意水準に一致する)。p-値が小さければ小さいほどより稀なケースが起きていることになり,故に帰無仮説が間違っていると考えることの確信度が高まる。p-値は帰無仮説を棄却する事の確信度,というあいまいな感覚値を数値化した有用な指標であると言える。
Ⅴ. まとめおよびその他のテストに関して
ここではA/Bテストの例しか取り上げなかったが,テストは様々な種類がある。それによって計算する統計量 T と T に従う分布は異なってくる。今までは標準正規分布に従う統計量を用いてきたが,その他にも t 分布・F 分布・χ^2 分布に従う統計量が存在する。それらはどれも出発点は中心極限定理と標準正規分布にある。ただサンプル数の大小,または分散が既知か未知かによって計算することのできないパラメータが存在するので,それを四則演算によって巧みに打ち消すようにして作った統計量が t 分布や F 分布に従うのだ。ただし,基本的にはどのテストにおいても,その概念は変わることは無い:
- 大数の弱法則および中心極限定理がテストを強力にサポートする。
- 棄却を目的として,帰無仮説をこしらえる。
- 帰無仮説の下,標本からある分布(正規分布・t分布・F分布・χ^2分布など)に従う統計量 T を求める。
- 統計量 T がその分布の元で稀なケースかどうかをチェックする。(p-値はどれ位稀なケースか、言い換えればどれ位の確信度を持って帰無仮説を棄却できるかを計るための、あらゆる統計量において有用な指標である。)
- 稀なケースであり,帰無仮説を疑う方が妥当であると判断できる場合は帰無仮説を棄却し、対立仮説を採択する。そうでないなら何もわからないと判断する。
- あらゆるテストは誤りの可能性を排除できない。また,第一種の誤り確率は有意水準に等しく制御可能であるが,第二種の誤りは制御不可能である。
興味を持たれた方は色々なパターンを調べて見て欲しい。また,第4回では他の様々なテストが事例とともに登場する。
A/Bテストの数理 - 第1回:人間の感覚のみでテスト結果を判定する事の難しさについて -
データ解析の重要性が認識されつつある(?)最近でさえも,A/Bテストを始めとしたテスト( = 統計的仮説検定:以後これをテストと呼ぶ)の重要性が注目される事は少なく,またテストの多くが正しく実施・解釈されていないという現状は今も昔も変わっていないように思われる。そこで,本シリーズではテストを正しく理解・実施・解釈してもらう事を目的として,テストのいろはをわかりやすく説明していきたいと思う。
スケジュール
-
スケジュール
- 第1回 [読み物]:『人間の感覚のみでテスト結果を判定する事の難しさについて』:人間の感覚のみでは正しくテストの判定を行うのは困難である事を説明し,テストになぜ統計的手法が必要かを感じてもらう。
- 第2回 [読み物]:『「何をテストすべきか」意義のある仮説を立てるためのヒント』:何をテストするか,つまり改善可能性のある効果的な仮説を見いだす事は,テストの実施方法うんぬんより本質的な問題である(かつ非常に難しい)。意義のある仮説を立てるためのヒントをいくつか考える。
- 第3回 [数学]:『テストの基本的概念と結果の解釈方法について』:テストの基本的な数学的概念を説明し,またテスト結果をどのように解釈するのかを説明する。
- 第3回補足 [数学]:『仮説検定の概念を改めて考える』:テストの概念をもう少し丁寧に説明する。
- 第4回 [数学]:『実分野における9個のテストパターンについて』その1,その2:オンラインゲーム解析とキャンペーン事例に見る,テストにおける統計量の計算について説明する。
- 第5回 [数学]:『実際にテストを体感する』:いくつかのテスト事例に対し,サンプルデータを提供し実際に統計量の算出を行ってもらう。新シリーズ:「Treasure Data Analytics」の枠組み内で紹介することになりました。
はじめに
多くの人はA/Bテストについて色々と間違った解釈を持ってしまっているように思われる。その代表が,
「A/Bテストは,実施結果の判断(AとBに違いがあるか否か)を(統計量に基づく仮説検定を全く行わないで)人間が判断するものである」
と思われていることである。また何らかの統計的手法によってそれを行う事は何となく知っていても,
「A/Bテストは,統計的手法それ自信が完全な意思決定を行ってくれる(白黒はっきりしてくれるもの)ものではなく,最終的には人間の判断に委ねられるものである」
という認識は実際に実施してみないと気づかないことかもしれない。(前者と後者は矛盾するように思われるかもしれないが,後者は第3回で説明するのでそのときに理解してもらえるはず)。第1回は前者の部分,テストにおいて人間の感覚による判定がいかに難しいかを説明する。
題材:A/Bテスト
今回のゴールは「人間の感覚だけで次に挙げるいくつかのA/Bテストの結果を正しく判断できますか?できないでしょう?」という主張を理解してもらうことにある。
よくあるA/Bテストの事例を題材にしてみた:
Q.「あるトップページの1つのリンクを青から赤に変える事によってリンク先へのアクセス数が増えるのでは無いかという仮説を持っている実験者は,その違いをテストしてみることにした。そこでオリジナルのトップページ(A)と1つのリンクを赤にしたトップページ(B)を作成し,だいたいアクセスが半々に独立かつランダムに割り振られるようにして,A, Bそれぞれのアクセス数に対してそのリンクが実際に押された比率(Conversion Rate)を比較することにした。双方1000アクセス来た時点で比率を計算すると,Aが40%であったのに対しBは60%であった。さてこの結果を受けてAとBには本当に差があると言え,赤リンクにしたことに効果があったと判定できるだろうか。」
※ 現実問題などの具体的な問題を考える上で1番始めにすべきことは,問題をより単純な数学問題へすり替える事である。比率の差を比較するA/Bテストの類いは,以下のような単純なコイン投げの数学問題と同型である。(AとBが同じ数学的構造を持つとき,AとBを同型と呼ぶことにする。例えばこちらで定義した「コンプガチャ問題」と「Coupon Collector's Problem」は同型である。)
Q'.「表の出る確率がわからないコインAとコインBがある。表の出る確率をそれぞれ p_a, p_b とする。コインAとコインBは違う確率を持ったものであるという仮説を持っている実験者は,その違いをテストしてみることにした。コインA,Bをそれぞれ 1000回ずつ投げてみて,表の出る比率を比べることでそれを確かめようとしている。今,コインAの比率が 40%であったのに対しコインBの比率は 60%であった。この実験からコインAとコインBには違いがある(i.e. p_a ≠ p_b)と言えるだろうか。」
(※ A/Bテストのより一般的な定義(スケルトン)は第3回で与える。 )
このA/Bテスト判定問題に関して,多くの人は以下のように答えるだろう:
「[根拠1] Aに比べてBは1.5倍も多く表を出しており,[根拠2] しかも1000回という十分なサンプル数がある。よってAとBには結果に明らかな違いがあり,赤リンク効果が実証されている!」
実はこの答えは正しく,人間の感覚もまんざらでは無いと思われた事でだろう。(そもそも,Bの方が数値的に良かったのであるので「効果があった」という答えしかないであろうと思う人もいるかもしれない。統計の背後には確率というものが常に存在しており,その"偶然"という要素の作用によって本来は効果に違いなんてなかったのに,たまたま数値的な違いが現れてしまったという事も有り得るのである。詳しくはコラム参照。)
次に上記問題のバリエーションを考えてみて欲しい。(類似の問題が並べられている故に解答に戸惑ってしまうかもしれないが,それぞれ独立した問題として考えて欲しい。)
- Q1. コインA,コインBをそれぞれ 10回投げてみて,40%, 60%であったとき
- Q2. コインA,コインBをそれぞれ 40回投げてみて,40%, 60%であったとき
- Q3. コインA,コインBをそれぞれ 100回投げてみて,40%, 60%であったとき
- Q4. コインA,コインBをそれぞれ 1000回投げてみて,40%, 60%であったとき(Q'. と同じ)
- Q5. コインA,コインBをそれぞれ 1,000回投げてみて,48%, 52%であったとき
- Q6. コインA,コインBをそれぞれ 1,000回投げてみて,47%, 53%であったとき
- Q7. コインAを 20回,コインBを 80回投げてみて,40%, 60%であったとき
さて,答えは以下となる(最後に手計算とRでの計算結果を載せている):
- Q1. → 「差があるとは言えない」
- Q2. → 「差があるとは言えない」
- Q3. → 「差があると言える」
- Q4. → 「差があると言える」
- Q5. → 「差があるとは言えない」
- Q6. → 「差があると言える」
- Q7. → 「差があるとは言えない」
このバリエーション問題の難しい(間違える)のは,人間の感覚的な判断を揺るがす以下の要素が含まれるからである:
- サンプル数が少ない場合:Q2, Q3のようにサンプル数が少ない場合。サンプル数が多い方が違いを見極めやすい事を感覚的には知っているが,数がどれくらいあれば良いのかはわからない。(そもそもサンプル数を増やすと,違いがあると言いやすくなるという根拠がどこにあるのかもわからないかも。)
- 比率の差が接近している場合:Q5., Q6のように比率が47%と53%や48%と52%のように接近している場合,(「微妙」という答えは無いため)違うと言える差の境界がわからない。
- サンプル数が偏る場合:Q7のようにサンプル数が偏っている場合,双方の結果を平等に眺めることが難しくなる。(注:「サンプル数」= 「コインを投げる回数」)
このようにテストにおいて「違いの差」を考える際には上記のような人間の感覚が類推できる範囲を超えた,「サンプル数や双方の数の偏りとの関連の考慮」などが必要となってしまう。故に人間の感覚でA/Bテストの結果を判断するのは難しいのである。
現実社会での事例
では実社会で僕たちが,本来は差が無いと考えられる結果に動揺させられている事例を2つ程挙げてみよう。(計算方法はエントリー最後に掲載)
1. 失業率
現在,労働力調査は,全国で無作為に抽出された約40,000世帯の世帯員のうち15歳以上の者約10万人を対象とし,その就業・不就業の状態を調査している。
全数調査では無い失業率は,もう1回調査を行ってみればその数値が前と異なっていることは大いに有り得る。にも関わらず本来悪化したとは言いいきれない失業率の0.1ポイントの増加(悪化)に対しても悲観的に報じられるメディアによって国民は不安に煽られてしまう。
問:「前月: 4.9%, 今月: 5.0%とした時,前月比較で0.1ポイントの失業率の増加は悪化したと言えるか? 」
答: 「悪化したとは言えない」
2. 年収500万円と2000万円の人の違い
「手柄を社内にアピールするか否か」 (page2)
年収500万円の300人と年収2000万人の200人に対する調査結果の解釈について。中には以下の様に年収間で差があるとは言い切れない結果もある。
問:「手柄を社内にアピールするか否かの調査結果は,年収間で差があると言えるか 」
答: 「差があるとは言えない」
※ 年収別の調査結果は,2×l 分割表の適合度検定の問題等,様々なテストを考える上で非常に興味深い。
コラム:テストに潜む ”偶然” のいたずらについて
統計の背後には必ず確率という概念が存在する。それを理解するために今度は僕たちはすでに答えを知っているという神の立場から,A/Bテストを考えてみることにしよう。
Case1: 『実はコインAとコインBは実は同じコインで,かつ表と裏が平等に出る( p_a = p_b = 1/2 )公平なコインである事を知っており,今これらのコインでテストしようとする実験者を眺めているとする。この時コインA, Bをそれぞれ10回投げた時,Aは表が出て4回出てBは6回出た。もう一度繰り返してみると,今度はAが2回,Bが8回であった』
Case2: 『今度はコインAの方がコインBより表が4倍出やすい( p_a = 4/5, p_b = 1/5 )とする。今これらのコインでテストしようとする実験者を眺めているとする。この時コインA, Bをそれぞれ10回投げた時,Aは表が出て4回出てBは6回出た。もう一度繰り返してみると,今度はAが2回,Bが8回であった』
Case1 の方は,10回のコイン投げるという実験を1セットと呼ぶなら,表が5回出るセットが最も多そうだけれども表が4回出ることも6回出るセットも十分に起こりうるだろう。よって実験者は「違いがあるとは言えない」と判断すべきと思うだろう。"偶然" Aの方は表が4回出てBの方は6回出た結果に対して,それを元が違うと判断するのは早計である,と。2回と8回出たケースに関しては,このセットはほとんど起こり得ないが確率 0 では無い。ただしこの場合は実験者は「違いがある」とまたも間違ってしまうが,答えを知らない立場からのその判断は賢明であると思うだろう。たまたま出にくい実験結果を得てしまった,運が悪かったねと言ってあげたくなる。(本来同じであることを違うと判断してしまうこの誤りは「第1種の誤り」と呼ばれていたりする。)
Case2 の方は,今度は本来コインは異なるものであるのに,4回と6回という結果を受けて実験者が「差が無いとは言い切れない」と判断しても仕方が無いと思うだろう。たいていはコインAとBで開きがあるケースが多いのに,運悪く両者の違いの小さなセットを得てしまったのだと。(違うのに同じと判断してしまうこの誤りは「第2種の誤り」と呼ばれていたりする。)
この2つのケースから言えるのは,答えを知らない立場の側が「賢明」と思われる判断を行っても,それが間違いであることが有り得ると言うことである。
僕たちは神ではないので答え(真の分布)を知ることはできない。よってその答えに対するヒント(サンプル)から答えを推定することしかできない。テストというのは統計的手法を持ってしても,偶然の ”いたずら” によって間違えてしまうこともあるのである。テストに対する統計的アプローチは,間違いの可能性は避けられないができるかぎり最適な方法を持って臨むことである。人間の感覚の判断というアプローチはこの偶然のいたずらによる影響と,「違い」の程度とサンプル数との関連を類推しきれない事の影響を受けてしまう故に,最適な方法とはほど遠いと考えられる。
問題の答え
「数学的ゲームデザイン」というアプローチ
前回の議論をより一般化した話です。数式も少なめ。実ビジネスにおいて数学がどこまで貢献できるのかというところを理解してもらい,少なからず関心を持って頂ければ幸いです。ただしあくまで読み物として捉え,実世界ビジネスにおける違法性など指摘をするのはやめて下さい。
目次
1. 『コンプガチャの数理 -コンプに必要な期待回数の計算方法について-』
3. 『コンプガチャの数理 -ガイドラインに基づいたゲームデザイン その1-』
4. 『コンプガチャの数理 -ガイドラインに基づいたゲームデザイン その2-』
定義
「数学的ゲームデザイン」とは,とある数学モデルのレールに沿ったゲームをデザインすることである。それによって,その背景にある種々の数学的性質を活用して優位な戦略を立てることが可能になる。
コンプガチャは,「The Coupon Collector's Problem」という数学モデルに基づいた数学的ゲームデザインの好例である。この例から学んだことは,
- 高々10種類のアイテムをコンプするだけでも,コンプまでに10万円を要するような確率設定を行うことができる。
- 「具体的な売上数値目標」を,「アイテム収集枚数ごとのユーザー数を調節する」ことで達成可能にするといった,戦略を実行可能なアクションスキームにまで落とし込むことができる。
であった。より一般的に言えば,数学的ゲームデザインを行うことは実世界のビジネス文脈において以下の様な性質を持つ:
- 人間の感覚的見積もりと真値の大きな乖離(錯覚と呼ばれたりする)を利用して,非合理的な行動に誘導する
- 調節可能なパラメータを提供側が初めから握っておくことで常に有利な戦略を立てることが可能になる
ところで,このように書くとこういったゲームはフェアで無い,ずるいゲームという印象を持つ人もいると思う。ここでは実世界におけるそういった評価は置いておき,以下の様にゲームの「公平性」を定義しておく:
本文脈において「フェアなゲームである」とは,ユーザー側に予めゲームのルールと必要なパラメータ値が明示されていることである。
コンプガチャの文脈において,このゲームがフェアであると言えるのは「アイテムの種類数と,各アイテムごとの出現確率が公開されている」場合である。なぜならこの場合においては,ユーザー側も「次に新しいアイテムが得られる確率」「あと何回でコンプできるかの期待回数」といった,現在の状況を把握し合理的に判断できる,提供側と同じ情報を得ることができるからである。
※ ただ実際はフェアなゲームであっても,ルールをきちんと把握しかつ状況を把握するための数学的手法を心得ていない人の方が多いし,提供側はそれを親切に教えてくれない。つまりほとんどの人においてはこのようなフェアなゲームでも初めからやや不利な状況に置かれている事になる。そこにさらに射幸心を仰ぐ戦略をぶつけてこられるのである。「リテラシーを高める」とは,情報と数学を駆使してそのような提供側の攻撃から防衛する手段を身につけることである。
※ あくまでも本文の話は数学の世界の話なので,以上の設定におけるこれ以上の深いつっこみは無しと言うことで。
Case 1: ルーレット
最も有名でわかりやすい数学的ゲームデザインはカジノにおけるルーレットである。ルーレットは 38 区分(1 - 36,0,00)の数字の中から1つが一様ランダムに選ばれる,最もベーシックな確率論に基づいたフェアなゲームである。故にある特定の数字・色・偶奇が出る確率も明確であり,また,0と00(色は緑)の存在によってどのように賭けてもその期待値の見積もりができ,それがユーザー側が不利であること(このことと本文脈での"フェア"とは関係ない)がすぐにわかる。
ルーレットの面白いところはこのルール設定に加えて,いわゆるユーザーの錯覚を誘う巧妙(?)な罠を仕込んでおり,ユーザーの選択肢を制御し,提供側がさらにゲームを有利に進めていることである。
多くのカジノには過去20回の試行の結果が派手に大きく掲示されており,これは多くの人に「ギャンブラーの誤謬」と呼ばれる錯覚を与えている。
- 直近の10回の試行が全て赤であったので,「次こそは」と黒に賭ける
- 過去20回で出現した数字は次は出にくいはずなので,それらを除外した数字のみを考慮範囲する
※ [2012/05/11] 以下,このような状況でも「次の出玉確率自身が変わることは無い」ので,「不利な選択=期待値が変わる」というようにとれる元の文脈を修正しました。
これらの行為は,実はユーザー自らが勝つ可能性を狭めていることになっている。毎回の試行は「独立」に行われているので過去の試行に依存することは無い。提供側はあえて過去の結果を見せることでユーザー側に「試行の独立」という概念をぼやけさせ,「過去との関連」を考慮した不利な選択を行わせているのである。
これらの行為は,実際は毎回の試行が独立であるはずなのに,過去の試行と関連しているように思わせている(バイアスを誘導する)。依然として赤黒共に出現確率は変わらないのに,ユーザー側では黒の方に偏った(条件付き)確率を想定してしまっている。
Case 2: ブラックジャック
一方,ブラックジャックも複雑であるが(おそらく)数学モデルに沿ったゲームデザインである。ルールも明白でフェアなゲームである。ここでブラックジャックを取り上げた理由は,ブラックジャックは他のカジノとは異質なケースであるからだ。他のカジノと同じように一見提供側に有利に作られたと思われるブラックジャックルールは,天才数学者 エドワード・O・ソープ によってその必勝方法(カードカウンティング)を見いだされ,ユーザー側にも有利なケースが存在してしまっていることである。フェアなゲームの上ではユーザー側もまた,ゲームを有利に進められる可能性がある。
さらにブラックジャックというゲームは「シャッフル」の難しさを利用することもできる(こちらは厳密に評価はできないが)。もし前回のカードの並びを記憶しており,今回のプレイにおいても十分なシャッフルが行われないまま開始されたとすると,前のカードの並びを受けて,次に出るカードがある程度予測できることになるのだ。
それでは,十分なシャッフルを達成するには何回カードをシャッフルしないといけないのだろうか?この解析は変動距離の概念と「マルコフ連鎖のカップリング」という手法を用いて評価される。結果は
n ln (n/ε) 回シャッフルした後では,シャッフルが十分でない確率は ε まで小さくなっている
ということである。具体的に 52枚 (n=52) のカードで 1% (ε=0.01) のシャッフル失敗に抑える設定の元では必要なシャッフル回数は 445回 も必要になることになる。
(現代のブラックジャックゲームはおそらく以上の事は全て考慮に入れられた上のルールの下で行われているような気がするので簡単には有利に進めさせてくれないと思われる)
※ 残りはベーシックな数学モデルの紹介と,基本的な解析結果である。より詳細な解析およびより具体的なゲームデザインについては触れていない。
Case 3. Birthday Paradox
非常に有名な問題である。ここでは閏年と双子の可能性を排除している。
問:「クラスに30人の生徒がいる。この時,(1) ある2人の誕生日が同じである,(2) どの2人も誕生日が同じで無い,どちらの方がより起こりやすいだろうか?」
答:(1)。約 70% の確率である2人の誕生日が同じである。また23人いれば,ある2人の誕生日が同じ事象が50%で起こりうる。
この問題は,365バリエーションもある誕生日においても,たった23人いれば誕生日が重複する可能性の方が高くなることを述べている。人間の感覚値と真値が乖離しているを表したわかりやすい例である。
一般に m 人,n 誕生日の設定の元では50%の閾値は概ね と見積もれる。例えば10万パターンのアバターを用意しても,372人のパーティーを作ってみるとそこにはアバターが重複しているメンバーが出る確率の方が大きい。
Case 4. Balls and Bins Problem
問:「n 個のボールと n 本のビンがある。ボールは各々のビンに投げ入れられるとし,投げ入れられるビンは n 本から独立かつ一様ランダムに選ばれる。この時,ビンの中の最多ボール数(最大内容量)はいくらくらいになるか?」
答:1に非常に近い確率で となる。
また非常に大きな n では,最大容量が 3 ln n / ln ln n より大きくなるのは 1 / n 程度でしか無いことも言える。
今(大きな n では無いが),20 回のぬいぐるみ投げゲームにおいて,(20のいずれかの)箱に入っているぬいぐるみの数が 8.2 個以上であるケースは 5% に過ぎない。どれかの箱に 9 個入っていればユーザーの勝ちであるとするならば,ほとんどのユーザーはこれを達成することはできない。
※ ビンとボールの問題は,前述の「Birthday Paradox」および「Coupon Collector's Problem」を包含する様々なパターンが考えられている問題である。また,解析手法も Poisson近似,マルコフ連鎖のカップリング,マルチンゲールなど多岐に及ぶ。
Case 5. Balls and Bins Problem (revised)
問:「n 個のボールと n 本のビンがある。ボールは各々のビンに投げ入れられるとし,今回の場合は投げ入れられるビンはランダムに 2 本選ばれることにする。そして選ばれたビンの内,容量が少ない方にボールが入れられる。つまりビン同士のボールの数をより"均質にする"という仕組みを導入する。この時,ビンの中の最多ボール数(最大内容量)はいくらくらいになるか?もしより一般に d 本選べるとしたらどうか?」
答:ビンを 2 本選ぶ場合は ln ln n / ln 2 + O(1),d>2 では ln ln n / ln d + O(1) となる。
この結果は次の様な興味深い考察を与えている。
Case 4 の場合(d=1)に比べて,d=2 の場合はその結果が指数的に減少している。つまりビンを2つ選んで少ない方に入れるという余地を与えることで最大容量を大幅に減らす結果になっている。しかしながら,d=2 から d=3 への変更はその減少は定数倍にとどまっている。d>3 の場合も高々定数倍の減少でしかない。
元の問題から一段階難易度が下がった時の劇的な変化を体感した後では,ユーザーは次の段階でも同じような変化量を期待してしまうが,実際はそれほど変化しないという一種の乖離を生んでしまう可能性を含んでいる。
Case 6. Coupon Collector's Problem
問:「全部で n 種類の応募シールがある。どのシリアルの箱にもどれか1種類の応募シールがある確率で入っていて,n 種類の応募シールを集めると懸賞をもらうことができる。いったい何箱のシリアルを買えば懸賞がもらえるのだろうか?」
答:シールが全て等確率ならば nH(n) 箱,シールが異なる確率であるなら,
。
Case 7. Coupon Collector's Problem (revised)
問:「全部で n 種類のシリアルが有り,それぞれには点数付きのシールが与えられている。ただし,ここではシリアルを購入しないと点数がわからないとする。集めたシールの点数の合計が全部で20点になると懸賞がもらえる。点数のバリエーションが 1点,1.5点,2点あるとして,懸賞をもらうのに必要なシリアルの購入数はいくらだろうか?」
答:しゅくだい
コンプガチャの数理 -コンプに必要な期待回数の計算方法について-
目次
1. 『コンプガチャの数理 -コンプに必要な期待回数の計算方法について-』
3. 『コンプガチャの数理 -ガイドラインに基づいたゲームデザイン その1-』
4. 『コンプガチャの数理 -ガイドラインに基づいたゲームデザイン その2-』
目的
コンプガチャのコンプに必要な回数を求める問題は「The Coupon Collector's Problem」と呼ばれる数学モデルの枠組みに沿った美しい問題である事を述べ,いくつかの有用な結果を示す。
※ あくまで個人研究のつもりで書いたので,色々不備があるかもしれません。その際は一言頂けると助かります。
定義
コンプガチャ問題を Coupon Collector's Problem に準じた形で書くと以下の様になる:
「全部で n 種類のアイテムがあって,1つのガチャの中にアイテムが1つ入っているけれども,ガチャを空けるまではその中身はわからない。今,アイテム集めに関しては他の人と協力しない(トレードや売買をしない)という前提の元で,n 種類のアイテムを全部コンプリートするのにいったいいくつのガチャを買わないといけないだろうか?」
※ 例えば n 種類の中の特定の m 種類(レアガチャ)を集めれば良いといった問題は今回は対象としていない。
結果
1. 全アイテムの出現確率が等確率の場合
全アイテムの出現確率が等確率,つまり 1/n の場合は大学学部レベルの数学でこの問題を解くことができる。
今, を新たなガチャが出るまでに買わないといけない数であるとする。n 種類のガチャを全て得るための回数を
とすると,本問題におけるゴールは
の期待値
を求める事に等しい。
であるから期待値の線形性より
であるので,
を求めるには任意の i において
を計算できれば良いことになる。さて,
の計算は任意の i で
が幾何分布に従っているという事実から簡単に求めることができる。
※ 幾何分布とは「確率 p で表が出るコイン投げを行ったとき,n 回目に初めて表が出る確率」を表現するものであり,
と表現される。p は幾何分布のパラメータと呼ばれる。この期待値 である。これは例えば p=1/2 のコイン投げにおいて、初めて表が出る期待回数は 2 回という事を示している。
今,既に i-1 種類のガチャを集めているとする。この時新しいアイテムが得られる確率は 1 から現在持っている i-1 種類のガチャが選ばれる確率を引けば良いので,
である。当たり前だが,この確率の示すところは,i (既に集めているアイテムの数)が大きくなれば (新しいアイテムが得られる確率)が小さくなっていくことである。
ところで、 はパラメータ
を持った幾何分布であるので,
である。よって
となる。ここで は Harmonic Number: H(n) と呼ばれる。
∴ n 種類全てのアイテムをコンプするために必要な期待回数は nH(n) 回である。
であるので,期待回数はまた とも書ける。
であるので,n=3 で 2n+α,n=8 で 3n+α,n=20 で 4n+α,n=150 で 5n+α n=3 で n+α,n=8 で 2n+α,n=20 で 3n+α,n=55 で 4n+α,n=150 で 5n+α 程度の回数を必要とする。
例
AKB48「ポスター44種類コンプでイベント招待」企画,「独禁法違反」のおそれで中止
解: 今44種類のポスターを全てコンプするのに必要な期待回数は 44*H(44) である。
Rでは H(n) を以下の様に定義することができる:
つまり44枚のポスターを全部コンプするのに必要なCDは192枚ということになる。CDは1250円であったらしいので、全部コンプするのに 1250*192 = 240,000(24万円!)かかることになる。
また、n を1から50まで動かした時の期待回数は以下の通り。
今求めているのはあくまで期待値であるので実際はこの期待値まわりの値にばらつく。
そのばらつき具合は Y がパラメータ p を持つ幾何分布であるとき,その分散が
であることを利用して、
となる。この結果に Chebychev の不等式を適用することで(導出省略)以下のさらに強い結果を言うことができる:
「2nln(n) 回ガチャを回してもまだアイテムをコンプできていない確率は 1/n 以下である」
先ほどのAKB48の例では「CDを 2*44*ln(44)=333 枚(416,250円)買ったとしてもまだポスターをコンプできない人は 2.3% 程度に過ぎない」,つまり50万円を持っておけば準備はほぼ万全と言える。
(Q. 以上の結果を踏まえると,ポスターのコンプリートセットを販売するとするなら,いくらの値段設定が妥当であろうか?例えば10万円なら本気でコンプリートしたい人には安い設定となる)
2. 出現確率が互いに異なる確率の場合
ここで考える問題は,全 3 種類のコンプガチャゲームがあったとき,その3種類の出現確率が () = (1/6, 1/3, 1/2) と異なって設定されている場合である。
一般にはこちらの状況の方が多いが,式の導出はなかなかのハイレベルなので結果のみを示すことにする。詳細は http://algo.inria.fr/flajolet/Publications/FlGaTh92.pdf を参照。
∴n 種類のアイテムをコンプするのに必要な期待回数は,
である。
(ただし )この結果より,以下の事がわかる:
- 等確率の設定よりもコンプに必要な回数は遙かに多くなる
- 出現確率のばらつきによってもコンプに必要な回数は変動する
- 300円ガチャであれば10種類のアイテム数でもコンプまでに10万円以上かかる設定が可能である
以下が主な数値結果。
# 3種類
- (1/3,1/3,1/3) -> 5.5回
- (1/6,1/3,1/2) -> 7.3回
- (1/10,4/10,5/10) -> 10.7回
# 20種類(括弧内は確率ではなくそれぞれのアイテムの重み)
- (1,1,...,1) [等確率] -> 72回,21,586円
- (1,1,1,1,1,10,...,10) [5個のレアイテムと15個のアイテム] -> 354回,106,195円
# 10種類(括弧内は確率ではなくそれぞれのアイテムの重み)
- (1,1,...,1) [等確率] -> 29回,8,787円
- (1,1,1,30,...,30) [3個の超レアイテムと7個のアイテム] -> 390回, 117,152円
R コードは本文の最後に記載。
感想
ソーシャルゲームのコンプガチャやAKBのポスター購入戦略のすごいところは,数学モデルのレールに沿った仕組みを実世界で提供することにより,物事を有利に進められる点である。例えばあるイベントにおいては本イベント期間での売上目標を x 円と定めたとすると,この目標は以下の具体的なアクションスキームまで落とし込むことができる:
- アイテムを n 種類用意する
- 確率テーブルを (p_1, p_2,...) に設定する
- 以下の様な見込みセグメントにおいて,ユーザー数 a, b,...人と期待金額 x_1, x_2,...円に設定する
- コンプするユーザー a 人 --(計算)--> x_1 円
- 3/4種類集めるユーザー b 人 --(計算)--> x_2 円
- 半分種類集めるユーザー c 人 --(計算)--> x_3 円
- ...
(以上のパラメータは全て事前に定める事ができる。)
後はイベントにおいて,各セグメントを達成するユーザー数が a, b, c,... となるように工夫をしていけば良い。
データマイニングがデータ(結果)から数学モデルを見いだし,調節可能なパラメータを見いだしそれを変更することで改善を図る戦略なのに対し,上記の戦略は数学理論に沿ったデザインを初めから提供することで調節可能なパラメータを初めから握っておくという対照的なものであると言える。
また,今後コンプガチャに代わるデザインを考える場合にも数学モデルに基づいたものを検討するのは有効な戦略と考える。「Coupon Collector's Problem」にも色々な派生があり,またより大きな視点で見れば Coupon Collector's Problem は「Balls and Bins Problem」の一部であると考えることができる。つまりこれらのモデルをうまくデザインすることができれば,それはまたコンプガチャと同じように結果が予測可能で具体的なアクションに落とし込むことができるゲームを作ることができるかもしれない。以下の問題と結果は,次のデザインを生み出すヒントになるかもしれない。
a. Birthday Paradox
「全 n 種類のアイテムの出現確率の等しいガチャがある。ゲームのルールを同じアイテムが 2 個揃った(つまり重複した)時点でユーザーにご褒美がもらえるとする。このとき, 回で初めて重複する確率が 1/2 以上になる」
b. Balls and Bins Problem
「全 n 種類のアイテムの出現確率の等しいガチャがある。今ユーザーは n 回ガチャを回すチャンスがあり,どれかのアイテムが k 個以上重複していれば(これを最大内容量と呼ぶ)ユーザーにご褒美がもらえるとする。このとき最大容量 k が 3ln(n) / ln(ln(n)) より大きくなるのは 1/n でしか無い。」
c. Coupon Collector's Problem
「より優しいガチャコンプ問題を考える。1つのガチャからは1種類のアイテムが得られるのでは無く,ランダムに選ばれた d 種類のアイテムが掲載されたカタログが得られ,ユーザーはそこからどれか 1 つのアイテムを選択することができる。ユーザーは合理的な選択,つまり自分が今持っていないアイテムを選択するという過程のもとでは,コンプまでの期待回数は
である。十分大きい n で と書ける。この結果は本文の結果よりも遙かに少ない。」
参考文献
- Probability and Computing: Randomized Algorithms and Probabilistic Analysis
- Randomized Algorithms (Cambridge International Series on Parallel Computation)
- The Generalized Coupon Collector Problem
- SOME NEW ASPECTS OF THE COUPON COLLECTOR’S PROBLEM
- Birthday paradox, coupon collectors, caching algorithms and self-organizing search
※ 数式に不備があれば教えて下さい。R のコードはより効率的な記述ができると思っているで,良いコードがあれば教えて下さい。
MongoDB JPの一年を振り返り、そして今後についてお話しします
MongoDB JPが発足してちょうど一年が経とうとしています。発足当時まだ学生だった頃の話です。初めは小さなコミュニティだったMongoDB JPも、現在では600名近いのGoogleグループのメンバーを抱え、毎回の勉強会でも100名以上の参加者に集まって頂くような規模にまで成長してきました。
この一年でMongoDBを実運用で使われているWeb企業さんもだいぶ増えてきました。多くの方の支えと協力があっての今もなお成長し続けている事に関しては感謝の気持ちでいっぱいです。
今回は技術の話しでは無く、以下の内容でMongoDB JPのこれまでの活動と現状を振り返り、そして今後について述べていきたいと思います。
アジェンダ
- MongoDB JPのこれまでの活動
- MongoDBと共に成長した一年間を簡単に振り返ります。
- MongoDB JPの現状の問題
- 金銭的な問題・ドキュメント整備の問題などについて。
- MongoDB JPのこれからについて
- 10genと共に今後は日本での本格展開に向けて動いていきます。
- 今後のMongoDBイベント
- 今年から来年にかけて、Mongoイベントは盛りだくさんです。
1. MongoDB JPのこれまでの活動
MongoDB JPはこれまでに6回の定例勉強会(最近の開催風景第5回・第6回)と、10gen主催の公式MongoDB Conferenceを1回、そしてソースコードリーディング分科会やその他の勉強会に招かれての発表など、たくさんの活動を行ってきました。僕がこれまでに書いたMongoDB関連の資料も20近くになりました。これまでの経緯を少し振り返っていきます。
第1回MongoDB勉強会
記念すべき12月の第1回勉強会はCouchDB JPの方と合同で開催しました。初めての主催側の勉強会という事で段取りなどに非常に苦労したことを覚えています。リラックスなCouchな皆さんには非常に助けられました。スタッフを募り・発表資料を作り・当日はあれこれ裏方で動く…当時はそんな大変な勉強会をこれから続けていけるのかと不安でした。
MongoDB Conference in Japan
3月には10gen主催のMongoDB Conference in Japan(通称 mongotokyo)を開催しました。10genの方と密にやり取りしながら、英文メールの書き方や簡単な会話のしかたを学びました。楽天さんに会場をお借りし、技評さんに告知をお願いし、スタッフと発表者を募集し…、これらも非常に大変でしたが、世界公式のカンファレンスを日本で行える嬉しさと誇りはその苦労を遙かに上回るものでした。例え個人であっても、OSSを通じて世界のトップエンジニアとつながれるチャンスはいくらでもあるんだなぁとその時強く感じました。今思えば蒼々たる方々に発表して頂け、カンファレンス自身も成功に終わったことはMongoDBの今後の可能性を確信させてくれ、大きな自信となるものでした。
そしてまた、この時に当時スタッフとして参加してくださっていた @understeer さんに出会えたことは、以後のMongoDB JPの安定かつ継続的な活動ができているという意味で非常に大きな事だったと思います。
MongoDB 勉強会@フューチャーアーキテクト
それ以降の勉強会は @understeer さんの協力のおかげでフューチャーアーキテクトさんで開催できることになりました。常に10名近くのフューチャー社内・そして今では社外の多くのスタッフの方が勉強会の進行を支えてくれることになり、僕は運営や金銭管理のオペレーションを全て任せてしまって発表と会の進行に専念することができるようになりました。会場誘導をはじめUstream、そして懇親会の集金や準備まで全てが彼らの完璧なオペレーションの元で遂行されています。僕自身、勉強会で発表することで誰よりも自分自身が勉強になっていますので、僕は当日の司会と発表をするだけで良いというのは本当にありがたい状況です。いつもMongoDB勉強会をさせてくださっているスタッフの皆さん、本当にありがとうございます。そしてそれからも宜しくお願いします。
2. MongoDB JPの現状の問題
さて、皆さんに支えられて成長してきたMongoDB JPですが、もちろん色々と問題を抱える事にもなります。
運営資金の問題
基本的にオープンなコミュニティでありますので、勉強会などは必要な最低限の経費のみ参加者から頂くことにしています。主におやつ代と懇親会費ですね。ただ100名を超える規模になりますと当日キャンセルの方も多く、予定していた懇親会参加人数を10-20名下回るということもありました。そういった場合は数万円の赤字となってしまい、コミュニティで負担することになります。現状で僕たちは5万円近くの累積赤字を抱えています。金銭管理をうまくやれていないことに関してはきちんと反省してアクションを起こしていかないと日々反省するばかりです。
会場の問題
いつもフューチャーさんのおかげで100名を超える規模で安定してやらせてもらっていますが、フューチャーさんの会場が借りれなくなった時点で色々と問題が発生します。100名を超える人数を収容する会場を見つける事、その会場をお借りするのに必要なお金、そしてそのお金をどう捻出していくのか、など色々と大変になってしまいます。
特に来年1月に開催する第2回MongoDBカンファレンスでは、多数の参加者を見込めることから300名以上を収容できる会場が良いわけですが、まともに借りれば百万円はかかりますし、それを実現するためにたくさんのスポンサーを集めないといけません。そのために日々の仕事の合間を縫ってスポンサーを探す営業活動などをしていかないといけない、そういった所に時間をとられる懸念がありました。今回は前回に引き続き、楽天さんのご厚意によって無料で大きな会場を貸して頂く事ができました。本当にありがとうございます。他にも同時通訳を採用するのか、もしそうならその費用をどう捻出するかなどなど、コミュニティがこれだけ大きくなるとお金と時間が個人レベルではまかなえないくらいたくさんかかってしまい、もはや今までのままでは存続維持ができない状況になりつつあります。
日本語ドキュメント整備の問題
これも非常にしんどい問題です。本家のドキュメントの更新が非常に早くて翻訳が追いつかない、常に古い情報しか提供できていないという状況にあります。また、現状でドキュメント翻訳に参加している人もほぼいない状況ですので現在はほとんど行われていない状況にあります。僕も最近ほとんど訳していません…すいません…
これはきちんと呼びかけを行っていないという僕のさぼりの問題なのですが、前述した更新の速さもあってなかなかしんどいです。元々英語のドキュメントを読んでもらうようにしてもらえばありがたいというのが本音だったりします(すいません…)。
3. MongoDB JPのこれからについて
日本の窓口・エンタープライズ
さて、このようにコミュニティが大きく活発で、またそれ故の問題点を多数かかえるMongoDB JPですが、現在一つの転換期を迎えようとしています。10genによるMongoDBの本格的な日本展開です。具体的には日本の中でMongoDBをサポートする窓口を設けること、また強力なパートナー企業さんを見つけ、スポンサーやエンタープライズへのMongoDBの普及を後押ししてもらう、などなどです。
現在はそのファーストステップであり、それらを実現するための活動を10genと一緒に積極的に行っていく、といった状況です。特にエンタープライズ向けへのMongoDB本格導入のために動いてくれ、将来的にMongoDBの日本の窓口の中心なってくれるパートナーさんとも手を組んでいます。彼らが10gen側と密にやりとりをしてくれ、既にエンタープライズ方面で活発に動いてくれています。僕も今後はエンタープライズの方々向けに資料を用意し、導入メリットや技術的な話しを紹介しに行くといった活動を増やしていこうと思っています。
なんにせよ、10genというアメリカのテクノロジーベンチャーが世界の中の日本という国に可能性を見いだしてくれたことはまずは非常に嬉しいことです。
ですので今後MongoDBの導入を検討されている企業さんがいらっしゃいましたら是非とも声をおかけ下さい。どのようなシーンでMongoDBが活用できるのか、そもそもMongoDBで何ができるのか、色々ご提案させて頂きます。僕としても新しいMongoDB活用事例に出会えることに関して非常にわくわくしています。
MongoDBとオープンコミュニティ
ただ僕自身、エンタープライズの領域やサポート窓口の部分は今の所は深く介入するつもりはなく、これからもMongoDBを愛する1ユーザーとして、オープンなコミュニティ活動を中心となって勢力的に行っていこうと考えています。
オープンソースの恩恵を享受している身として、その恩返しのためにもこの活動を継続的に行っていくことは僕たちエンジニアに課せられた使命でもあります。また今まで一緒にコミュニティを育ててきたMongoな面々、 @understeer さん、 @uorat さん、 @ixixi さんを代表するフューチャーのMongoスタッフの皆さん、ソースレベルでMongoDBを語れるPFIの @repeatedly さん・ @nobu_k さん、ソースコードリーディング主催者の @choplin さん、そして人生の師である @bibrost 師、またMongoDB立ち上げを後押ししてくれ、コミュニティにいつも参加してくださっている @cakephper さん、宴会部長 @basuke さん、その他多数のメンバー(書ききれなくてすいません…)と共に今後ともMongoDBを通じた交流と発信を行っていくつもりです。今後とも宜しくお願いします。
4. 今後のMongoDBイベント
今後もMongoDBイベント盛りだくさんです。特に来年1月18日のmongotokyo2012は10gen側からPresidentを迎え、300名を超える規模で開催したいと考えております。ふるってご参加下さい!
mongotokyo2012について
既に募集の方が始まっています。開催一ヶ月前まではEarly Birdという通常より安い参加費で登録できます。一ヶ月を切りますと、General Admissionの価格になりますのでご注意下さい。また楽天の社員の方・発表者およびスタッフの方の参加日は無料です。ひとまずここで登録せずにお待ち下さい。本カンファレンスでは懇親会の費用をすべてこちらで負担します、カンファレンス後の懇親会まで、是非ともご参加下さい!
| 日付 | タイトル |
| 2011/11/15(火) | 「第7回 MongoDB 勉強会 in Tokyo」〜今年最後のMongoイベント〜 |
| 2011/11/19(土)-20(日) | オープンソースカンファレンス2011 |
| 2011/11/19(土) | 楽天テクノロジーカンファレンス2011 |
| 2011/12/7-9 | MongoDB Leader Summit & MongoSV *海外に行ってきます! |
| 2012/1/18(水) | Mongo Tokyo 2012 |
| 2012/1/27(金) | エンジニアサポート新年会 |
今後ともMongoDB JP をどうぞ宜しくお願いします!
MongoDBの新機能:ジャーナリングについて詳しく
v1.8でMongoDBはジャーナリングと呼ばれる機能が新たに加わりました。今日はMongoDBのジャーナリングについて、実際にどのような処理が行われているのかを確認しながら、丁寧に見ていくことにしましょう。※なお、ジャーナリングという言葉自身、Mongoにこの機能が実装されるまで深く意識するようなことはありませんでした。解釈の部分で誤りなどがあるかもしれません、その際はご指摘していただけると幸いです。
ジャーナリングによってデータの堅牢性が格段に高まった
v1.8でジャーナリング機能が追加されたことによって、シングルサーバーにおけるデータの堅牢性がさらに高まりました。ジャーナリングという言葉は主にファイルシステムの分野においてかなり前から議論され、改善が進められてきた機能です。この意味におけるジャーナリングの目的はファイルシステム全体を保護することであり、そのためにメタデータの整合性を保持するために処理が施されるのが一般的なものです。一方、データベースで用いられるジャーナリングの目的は主にデータの保全であり、サーバーの障害からデータの損失をいかに最小限に抑えられるか、という目的で処理が施されます。もちろんMongoDBにおけるジャーナリングの目的も後者に該当します。
また、サーバーが完全に再起不能な状態に陥ってしまう状況に備えたデータ保全対策も重要で、その場合の対策は物理的に異なるサーバーにReplica Setを(またはMaster/Slave)構成するといった事が必要です。MongoDBでは従来のReplica Setによるデータ保全に加えて、ジャーナリング機能が今回新たに加わった形でシングルサーバーに対しての強力なデータ保全機能が備わりました。これによりサーバーダウンによるデータの損失を最小限にとどめることができ、またスムーズなリカバリが可能になりました。
実はジャーナリングが導入される前のバージョンまでは、シングルサーバーに対してはそれほど強力なデータの保全機能を備えているわけではありませんでした。次の章では、まずジャーナリングが追加される前のv1.6が抱えていた問題点を指摘し、それがジャーナリングによってどのように改善されるのかを示すことにします。
insertなどのデータ変更のディスクへの反映は60秒に1回
MongoDBを使用する多くの場合、各種言語ドライバを介してMongoDBへデータ処理を行うはずです。その際に注意して欲しいのは、多くのドライバのデータのinsertは"fire-and-forget"と呼ばれ、毎回のinsert実行後、それが実際にディスクに書き込まれたかを確認せずに次の処理を次々に実行します。基本的にはupdate等のクエリに対しても同じです、これらのオペレーション併せて「データ変更処理」と呼ぶことにします。
この理由の1つに、MongoDBではinsert処理実行後すぐにデータがディスクに書き込まれるわけではないというのが挙げられます。まずはメモリに書き込まれ、(デフォルトでは)60秒に1回、メモリ上の全てのデータがディスクに書き込まれるという処理が行われています。これによって大量のデータを効率良くかつ高速に書き込めるようになっているのですが、これはメモリからディスクへの書き込みが行われる前にサーバーのダウンなどの何らかの問題が生じた場合にはまだディスクに書き込まれていなかったデータは完全に消失することになってしまうというデメリットも持っています。つまりデフォルトでは最悪60秒の間にinsertされたデータが丸々失われてしまうリスクを背負っていることになります。
ただ、この問題への対応策は既に2点用意されています。
1つは起動時のコマンドラインオプション"--syncdelay"によってディスクへのフラッシュ間隔を任意の秒数に変更することです。ただしこの設定を短い秒数に変更することで、Replica SetsやMaster/Slave環境を構成している場合はメンバーとの同期のための通信量が増えてしまい、大きな負荷となりえます。シングルサーバーで稼働している場合以外にはこの値を減少させることは推奨されていません。
2つ目は毎回のinsertの実行結果を確認するオプションがドライバに備わっているはず("safe"モード、または "set write concern"と呼ばれているコマンドです。)ですのでそれを使用する事です。このオプションを使用する事で、毎回のinsert()コマンドの後にgetLastError()コマンドを実行するようになります。このgetLastError()コマンドは、直前のオペレーションが成功したか否かを確認するコマンドです。またこのコマンドを実行することでデータに変更が加えられるオペレーションに対しては即座にディスクに書き込まれるようになります。ただしこのモードを使用すると(当たり前ですが)明らかに処理速度が低下します。MongoDBを利用する際には"critical"なデータと"non-critical"なデータという区別を持ち続け、それに併せた適切なデータ変更処理を行うようにしてください。
以上をまとめますと、MongoDBのデフォルトの振る舞いは"non-critical"なデータを想定したパフォーマンス重視に触れた設定になっています。安全なデータ変更処理を行う場合は、パフォーマンスを多少犠牲にしてでも上に述べた2つの施策(特に後者)を必ず行うようにして下さい。
ジャーナリングがデータの保全性を格段に高める第3の手段を与えてくれた
そしてv1.8で第3の手段となるジャーナリング機能によって、先ほど述べたデータ損失のリスクを大幅に低減されることになりました。
ジャーナリング機能を有効にして起動されたMongoDBは、実際にオペレーションを実行してデータに変更が加えられる前にこのオペレーション自身を追記専用の先行書き込みログ、ジャーナルファイルという特殊なファイルに書き込みます。より厳密に言えば100ミリ秒に1回、グループコミットという手法を用いてジャーナルファイルにオペレーションを書き込んでいきます。
このジャーナルファイルへの先行書き込みによって、インデックス作成などのデータの変更処理の実行途中、あるいはいくつかのデータがディスクにフラッシュされていない状況でサーバーがダウンしてしまったとしても、再起動時にそのオペレーションを再実行することでデータのリカバリができるようになります。ジャーナル機能をオンにしたMongoDBでは再起動時にクライアントから処理を受け付ける状態に入る前に、ジャーナルファイルに記録されたオペレーションを再実行してデータのリカバリが行うようになります。これによって今まで最悪60秒間のデータが全て失われてしまう可能性のあったものが、100ミリ秒間のデータの損失のみで済むようになりました。また、今まで必要だったmongod.lockの削除と、起動後のdb.repairDatabase()の実行も不要になりました。
このようにジャーナリングはデータの保全性に対して非常に大きな改善をもたらしてくれました。ただし、毎回データに変更を与えるオペレーションが先行してログに書き込まれる事になるので、それなりにパフォーマンスが落ちてしまう事はさけられません。記事、MongoDB Journaling Performance - Single Server Durabilityでは、ジャーナリングによって30%程度パフォーマンスが落ちてしまったという報告がされています。まだこの機能が登場して間もないことやこのようなパフォーマンスの問題もあり、v1.8においてはジャーナリングはデフォルトの機能にはなりませんでした。jounalingを使用するかどうかは、MongoDBをどのような目的や環境で利用しているかによって判断すべきでしょう。ただし今後ジャーナリングのグループコミットを行う間隔の改善や種々のパフォーマンスの改善がある程度進んだ段階でデフォルトの機能になる事でしょう。
従来のダウンからの復帰に必要な手順
さて、実際にジャーナリングの振る舞いを確認する前に、先ほど触れた言葉、mongod.lock、db.repairDatabase()に関する従来のサーバーダウンから復帰の手順についてお話ししておきます。
mongodが正常に終了されなかった場合、手動で再起動して正常な状態に復帰させるには以下の2つの手順が必要になってきます:
起動前に mongod.lock ファイルを削除する
mongodの起動時にはデータディレクトリの中にはmongod.lockというファイルが作成されます。また、正常終了時にはこのファイルは削除されます。mongod.lockの主な役割は正常終了されたか否かをファイルの存在によって確認することと、1つのデータディレクトリに1つのmongodしかアクセスできないようにブロックする役割です。異常終了の場合はこのファイルが残ることになり、再起動する場合には警告が出てこのファイルを削除しない限り起動することができません。この手順の詳細は後ほど具体的に説明しますのでここでは割愛させて頂きます。
起動後、db.repairDatabase()を実行して全データが壊れていないかのチェックを行う
また、いくつかのデータが破損している可能性がありますので起動後はまずdb.repairDatabase()というコマンドを実行して全データのスキャンを行う必要があります。このdb.repairDatabase()コマンドは全データが壊れていないかを確認するとともにデフラグのような役割も担います。ただ、このコマンドはデータベースの規模が大きいと(ロックはしないものの)パフォーマンスの大幅な低下と、非常に時間がかかってしまう事には注意しないといけません。また、実行のためにテンポラリファイルをdbpath内に新たに作成することを知っておかないといけません。
実際にジャーナリングの動作を確認してみる
それではここからは実際に手を動かし、mondodのサーバーログを確認しながらジャーナリングの動作に対する理解を深めることにしましょう。
journalサブディレクトリが作成され、ジャーナルファイルが作成されていることを確認する
mongodの起動時に--journalオプションをつけて起動してみましょう、ここではdbpathはdataディレクトリを指定しています。そして早速mongodのサーバーログを確認してみましょう。[1]で"journal dir=data/journal" として、なにやら新しいディレクトリがdbpath以下に作成されたのがわかります。[2]では"recover : no journal files present, no recovery needed"と書かれていますね。"recover"を行おうとしたけれども、ジャーナルファイルが見つからなかったのでその必要がない事が書かれています。その後、[3]でmongodはクライアントからの接続待ちの状態になります。(今回は必要な部分しか抜粋していません。)
$ mongod --journal --dbpath data Sun Jun 5 22:33:13 [initandlisten] MongoDB starting : pid=50557 port=27017 dbpath=data 64-bit Sun Jun 5 22:33:13 [initandlisten] db version v1.8.0, pdfile version 4.5 [1]Sun Jun 5 22:33:13 [initandlisten] journal dir=data/journal [2]Sun Jun 5 22:33:13 [initandlisten] recover : no journal files present, no recovery needed [3]Sun Jun 5 22:33:13 [initandlisten] waiting for connections on port 27017 Sun Jun 5 22:33:13 [websvr] web admin interface listening on port 28017 ...
まず[1]で実際にdbpathにjournalサブディレクトリが作成された事を確認してみましょう:
$ ls data journal mongod.lock test.0 test.1 test.ns
確かに作成されていることが確認できました。さらにjournalサブディレクトリの中を確認してみます:
$ ls -lh data/journal/ total 24 -rw------- 1 doryokujin staff 8.0K 6 5 22:55 j._0 -rw------- 1 doryokujin staff 88B 6 5 22:56 lsn
j._0 というファイルとlsnというファイルが作成されているのがわかります。どちらもバイナリファイルですので中身を確認することはできません。それではここでtestデータベースのmycollコレクションに対して100,000件の挿入を行ってみます:
$ mongo localhost:27017/test #<host>:<port>/<dbname>
> for(var n=0; n<100000; n++){ db.mycoll.insert( { "n": n } ); }ここでもう一度journalサブディレクトリを確認してみます:
$ ls -lh data/journal/ total 23696 -rw------- 1 doryokujin staff 12M 6 5 23:19 j._0 -rw------- 1 doryokujin staff 88B 6 5 23:19 lsn
j._0ファイルサイズが増えているのが確認できました。この j._0ファイルは前述したジャーナルファイルと呼ばれるもので、データに対して更新が行われた際のオペレーションが全て記録されています。インデックスの作成もジャーナルファイルに記録されます:
> db.mycoll.ensureIndex({"n":1})このオペレーションに対してもジャーナルファイルに記録されているのが確認できます:
$ ls -lh data/journal/ total 30280 -rw------- 1 doryokujin staff 15M 6 5 23:29 j._0 -rw------- 1 doryokujin staff 88B 6 5 23:29 lsn
ジャーナルファイルはそのファイルサイズが1GBに達した時点でローテートされj._0, j._1,...という名前で保存されていきます。また、古くなったジャーナルファイルは自然に削除されるため、通常運用においては2つから3つのジャーナルファイルが存在している状況になります。ただし、念のためにジャーナルファイル用に10GB程度の空き容量を確保するようにしておいて下さい。また、データの読み取りに関するオペレーションは何回行ってもジャーナルファイルには記述されません:
> var ary=[];
> for(var n=0; n<1000; n++){ ary[n]=db.mycoll.findOne( { "n": n } ); }
> ary
[
{
"_id" : ObjectId("4deb904e79d55a3e071f21a9"),
"n" : 0
},
{
"_id" : ObjectId("4deb904e79d55a3e071f21aa"),
"n" : 1
},
...$ ls -lh data/journal/ total 30280 -rw------- 1 doryokujin staff 15M 6 5 23:29 j._0 -rw------- 1 doryokujin staff 88B 6 5 23:37 lsn
正常終了時から再起動までの動作を確認する
ここからはmongodの正常終了・異常終了の際のジャーナリング機能周辺の挙動を確認してみることにしましょう。まずは正常終了させるために、起動している27017のmondodに対してCTRL+Cを押します。するとmongodのサーバーログは正常に終了処理を開始します。[1]に"shutdown: journalCleanup..."という表示が出ていますね、ここでジャーナルファイルのクリーンアップが行われているようです。[2]でジャーナルファイルが削除されているのが確認できます。[3]でmongod.lockファイルが削除され、[4]で正常な終了処理が完了したという通知とともに、mongodサーバーが終了します。
... Sun Jun 5 22:45:30 [interruptThread] shutdown: closing all files... Sun Jun 5 22:45:30 closeAllFiles() finished [1]Sun Jun 5 22:45:30 [interruptThread] shutdown: journalCleanup... [2]Sun Jun 5 22:45:30 [interruptThread] removeJournalFiles [3]Sun Jun 5 22:45:30 [interruptThread] shutdown: removing fs lock... [4]Sun Jun 5 22:45:30 dbexit: really exiting now
このように、正常な終了処理が行われるとjournalサブディレクト内のジャーナルファイルは全て削除されます。正常に終了したのですから、終了前の全てのデータ変更オペレーションはディスクに反映されていることが保証されていますので、次の起動の際にジャーナルファイルを保存しておく必要もないわけです。
異常終了時から再起動までの動作を確認する(ジャーナリング機能を有効にしていない場合)
それではここでmongodを意図的に異常終了(ダウン)させてみますが、ここではさらにジャーナリング機能を有効にした場合とそうでない場合でその挙動の違いを確認することにします。まずは--journalオプションなしで起動し、newcollコレクションに対して100,000件のデータ挿入してみましょう。
$ mongod --dbpath data
> for(var n=0; n<100000; n++){ db.newcoll.insert( { "n": n } ); }この操作の後にmongodを強制的にシャットダウンさせます。
$ ps aux | grep mongod | grep -v grep doryokujin 35401 16.4 0.5 2675212 22240 s015 S+ 11:54PM 0:00.61 mongod --dbpath data $ sudo kill -KILL 35401
強制終了されたmongodに対して再起動しようとすると前述したとおり、以下の様な警告が出て起動できません。
mongod --dbpath data Sun Jun 5 23:56:48 [initandlisten] MongoDB starting : pid=42647 port=27017 dbpath=data 64-bit Sun Jun 5 23:56:48 [initandlisten] db version v1.8.0, pdfile version 4.5 Sun Jun 5 23:56:48 [initandlisten] git version: 9c28b1d608df0ed6ebe791f63682370082da41c0 Sun Jun 5 23:56:48 [initandlisten] build sys info: Darwin erh2.10gen.cc 9.6.0 Darwin Kernel Version 9.6.0: Mon Nov 24 17:37:00 PST 2008; root:xnu-1228.9.59~1/RELEASE_I386 i386 BOOST_LIB_VERSION=1_40 ************** [1]old lock file: data/mongod.lock. probably means unclean shutdown [2]recommend removing file and running --repair see: http://dochub.mongodb.org/core/repair for more information ************* Sun Jun 5 23:56:48 [initandlisten] exception in initAndListen std::exception: old lock file, terminating Sun Jun 5 23:56:48 dbexit: Sun Jun 5 23:56:48 [initandlisten] shutdown: going to close listening sockets... Sun Jun 5 23:56:48 [initandlisten] shutdown: going to flush diaglog... Sun Jun 5 23:56:48 [initandlisten] shutdown: going to close sockets... Sun Jun 5 23:56:48 [initandlisten] shutdown: waiting for fs preallocator... Sun Jun 5 23:56:48 [initandlisten] shutdown: closing all files... Sun Jun 5 23:56:48 closeAllFiles() finished Sun Jun 5 23:56:48 dbexit: really exiting now
[1]で正常終了時には削除されるはずのdata/mongod.lock が残っているとの警告が出されていますね。そして[2]でこのファイルを削除して再起動し、reparコマンドを実行する事を勧めてきています。先ほどは記述しませんでしたが、repairコマンドは、起動後にdb.repairDatabase()を実行する以外に、起動の際に--repair コマンドラインオプションをつけることでも同じことが行えます。また、mongod.lockの削除の際はくれぐれも他のファイルやディレクトリを削除しないように注意して下さい。
$ rm data/mongod.lock $ mongod --repair --dbpath data
このように--journalオプションをつけずに復帰した場合は強制終了するまでにディスクに書き込まれていたデータだけが反映されており、実行途中のもの、実行されたもののまだディスクにフラッシュされていないデータはディスクに反映しないまま消失してしまいます。
異常終了時から再起動までの動作を確認する(ジャーナリング機能を有効にしている場合)
それでは次に--journalオプションをつけて起動し、前回使用したnewcollコレクションを一度ドロップしてから同じ処理を行ってみます。
$ mongod --journal --dbpath data
> db.newcoll.drop()
true
> for(var n=0; n<100000; n++){ db.newcoll.insert( { "n": n } ); }
$ ps aux | grep mongod
doryokujin 71504 17.2 0.2 2889368 6684 s015 R+ 12:05AM 0:01.34 mongod --journal --dbpath data
$ sudo kill -KILL 71504それでは--journalオプションをつけたままmongodを再起動してみましょう。そうすると今度は警告も出ずに再起動することができます。サーバーログを見てみましょう:
$ mongod --journal --dbpath data Mon Jun 6 00:08:24 [initandlisten] MongoDB starting : pid=83165 port=27017 dbpath=data 64-bit Mon Jun 6 00:08:24 [initandlisten] db version v1.8.0, pdfile version 4.5 Mon Jun 6 00:08:24 [initandlisten] git version: 9c28b1d608df0ed6ebe791f63682370082da41c0 Mon Jun 6 00:08:24 [initandlisten] build sys info: Darwin erh2.10gen.cc 9.6.0 Darwin Kernel Version 9.6.0: Mon Nov 24 17:37:00 PST 2008; root:xnu-1228.9.59~1/RELEASE_I386 i386 BOOST_LIB_VERSION=1_40 [1]Mon Jun 6 00:08:24 [initandlisten] journal dir=data/journal [2]Mon Jun 6 00:08:24 [initandlisten] recover begin [3]Mon Jun 6 00:08:24 [initandlisten] recover lsn: 0 [4]Mon Jun 6 00:08:24 [initandlisten] recover data/journal/j._0 [5]Mon Jun 6 00:08:26 [initandlisten] recover cleaning up [6]Mon Jun 6 00:08:26 [initandlisten] removeJournalFiles [7]Mon Jun 6 00:08:26 [initandlisten] recover done Mon Jun 6 00:08:26 [dur] lsn set 0 Mon Jun 6 00:08:26 [initandlisten] waiting for connections on port 27017 Mon Jun 6 00:08:26 [websvr] web admin interface listening on port 28017
[1]でジャーナルディレクトリの存在を確認し、[2]でrecover(リカバリ)を開始したことを述べています。[3]でlsnファイルから必要なジャーナルファイルを確認し、[4]でジャーナルファイル: j._0 に記述されたオペレーションを実行してリカバリを行っています。これにより、実行されたものの、ディスクに書き込まれていないデータをDBに反映することができます。これにより実際に実行されたオペレーションに対しては、リカバリ時に再実行されることによってデータの変更が保証されることになります。そして[5]で正常にリカバリが行われ、[6]でジャーナルファイルを削除し、[7]でリカバリが終了したことが述べられています。このように、サーバーログを見ればジャーナリング有効時の挙動を理解することが出来ます。
まとめ
さて、いかがでしたでしょうか?途中でも触れましたが、ジャーナリングはまだ導入されたばかりの機能であり、今後はグループコミットのタイミングの短縮化など、より精錬され、デフォルトの機能になることは間違いありませんので、その仕組みがどんなものでどれだけ重要な機能であるかを理解しておくことは非常に重要です。この記事によってその助けになれば幸いです。それではまた。
Sharding を使いこなすための5つのTips
@doryokujinです。今日も相変わらずMongoDBの、そしてShardingに関する記事を書こうと思います。
…と、その前にお知らせです!6月は2つのMongoDB勉強会を予定しております、是非ご参加下さい!
・2011年6月11日(土) 「第4回 MongoDB 勉強会 in Tokyo」@フューチャーアーキテクト ・2011年6月28日(火)「第1回 MongoDB ソースコードリーディング」@PFI
さて、それでは本題に入りたいと思います。
MongoDBのShardingといえば、
・初期設定やShardの追加・削除といった導入の容易さ
・Shardの面倒をMongo側がずっと見てくれるという管理の容易さ
を備えていると言うことで興味を持っておられる方も多数いると思います。
しかしその一方で実際にSharding環境を導入している方々の中の多くは、遭遇する様々な不都合や不整合に頭を悩まし、初期設定のミスで取り戻しのつかない状況に陥っていたりと、想定していた以上の苦労を強いられているように思われます。確かに現バージョン(v1.8)のMongoDBのShardingはまだまだ扱いが難しく、出来る限り「Shardingを使わない」方向で検討を進める方が得策である場合も多くあるような気がします。しかしきちんと対処法を身につけておきさえすれば、そういった起こりうるShardingの種々の問題に立ち向かうことができるはずです。
今日は少しマニアックな内容ですがShardingについて、知っておくと将来きっと役立つであろう5つのTipsを紹介したいと思います。
MongoDBのShardingはその余りある欠点を補うほどに強力です。大規模なSharding環境では、TBを超えるデータをあたかもシングルサーバーのMongoDBを相手にしているように簡単に扱え(若干言い過ぎですが…)、Replicationと連携した「大規模データストレージ」としての役割と、Mongo MapReduceやRedisやHadoopとの連携した「大規模データ解析基盤」としての役割を高い次元で両立させることができます。
この事はログ解析の観点で言えばScribeやFlume等で多数のサーバーに分散された大規模ログを定常的にMongoDBに集約させつつ、Mongo ShellからMap Reduceをさらっと記述して実行して、非バッチな処理やごく一部の領域にしか存在しない対象の解析でもインデックスなどを活用して高速かつ手軽に実行することができるようになる事を意味しています。Webアプリケーションの観点で言えば、あらゆるユーザーデータをMongoDBに格納し、一方バックグラウンドではリアルタイムに集計やクラスタリングアルゴリズムなどを走らせ、ユーザー単位でのパラメータの最適化やデータに基づいたアクションを即座にアプリケーションに反映することができる事を意味しています。
Sharding 5 Tips
0. 準備 〜自動Shardingと自動Balancing機能、そしてChunkという概念を知る〜
1. Primary Shardを活用する 〜Primary Shardの存在を知る〜
2. Chunkの事前分割 〜運用開始からデータを分散させる〜
3. Chunkの手動マイグレーション 〜安全に効率的にChunkを移動する〜
4. Chunkの手動分割&マイグレーション 〜動かないChunkを移動する〜
5. Shardの状態を監視する 〜有用な2つのコマンド〜
0. 準備 〜自動Shardingと自動Balancing機能、そしてChunkという概念を知ろう〜
ここではMongo Shardingの基本的な概念について簡単に解説したいと思います。「自動Sharding」とは挿入されるデータに対して、そのデータがどのShardに入るべきかを決定して振り分けてくれる機能です。より具体的に言えば、Sharding環境においてMongoDBはInsertされたドキュメントを(最初に設定した)ShardKeyの値に基づいて振り分けます。Sharding環境ではドキュメントの集合である"Chunk"という単位を持ち、このChunk単位で分割や移動が行われます。それぞれのChunkは他と重複しないShardKeyのレンジを持っています。例えばChunkAは [ "a", "k" ), ChunkBが [ "k", "{" ) のレンジを持っていたとすると、ShardKeyのイニシャルが"a"から"j"までの値を持つドキュメントはChunkAに、"k"から"z"までを持つドキュメントはChunkBに属します。"{" は "z" の次の順序を持つ値です。例えば"inoue" の値を持つドキュメントは ChunkA に、"takahiro" を持つドキュメントは ChunkB に属する事になります。繰り返しますが、このChunkがShard間を移動したり分割されたりします。1つ1つのドキュメント単位でそれらが行われることが無いことにはくれぐれも注意して下さい。
各Chunkはそのレンジが重複することは無く、またカバーしていないレンジもありません。先ほどの例では実は最低でもさらに後2つのChunkが存在します。それは [ -∞, "a" ) と [ "{", ∞ ] です。そして1つのChunkがデフォルトで200MB(Sharding開始時は64MB)以上のサイズに膨れあがると、Chunkはそれを等分割するキーによって分割されます。例えば ChunkA は [ "a", "g" ) と [ "g", "k" ) に分割されたりします。データ流入量が増え、Chunkの分割があちこちで行われるようになると、Shard間でChunkの数にばらつきが起こってきます。ドキュメントのShardKeyが特定のレンジ、つまり特定のChunkに集中する場合はそのShard内でたくさん分割が行われる事になります。これはある程度避けられない事であり、またデータローカリティを強く意識するならこの現象は必ずしも悪いものとも言い切れません。
MongoDBでは現在アクセスされているShardのChunkの数とクラスタ内で最小のChunk数を持つShardとの数の差を計算しており、その差が10以上になったときに、「Shard間に偏りが起こっている」と認識され、Chunk数が大のところから小のところへChunkの移動(マイグレーション)が行われます。これを自動Balancing機能と呼び、バックグラウンドでShard間のデータサイズを均質に保ち続けようとしてくれる親切な機能です。
このように、MongoDBのShardingは自動Sharding機能と自動Balancing(とReplica Sets の自動フェイルオーバー機能)によって容易にスケールさせる事が可能です。その他のShardingの機能についてや、ここで取り上げなかったSharding環境で起こる様々な問題については過去の資料をご覧下さい。
1. Primary Shardを活用する 〜Primary Shardの存在を知ろう〜
MongoDBには"Primary Shard"という概念があります。これは運用開始直後の数個しかないChunkが保存される初期Shardであり、MapReduceのOutputCollectionが作成される場所であり、その他様々なケースで優先的に使われるShardです。このPrimary Shardの存在を知り、適切な設定を行っておく事は以下の意味で非常に有用です。
・メモリやCPUの優秀なマシンを割り降ることで初期段階のデータの局所集中に耐える
・Primary ShardをSSD上に配置し、Map Reduceなどの出力を高速に行う
この2つの説明に入る前に、まずはShardingの構成について簡単にお話しておきます。
Sharding の初期構成
※ここでは簡単なShardingを用意する時間が無かったので、現在使用しているSharding環境を流用させて頂きます。
# 25のShard ( With Replica Sets ) を追加(24HDD + 1SSD)
# HDD
> db.adminCommand( { addshard: "shard00/delta1:2400,delta2:2400", name: "shard00" } )
> db.adminCommand( { addshard: "shard01/delta1:2401,delta2:2401", name: "shard01" } )
...
> db.adminCommand( { addshard: "shard22/delta6:2422,delta5:2422", name: "shard22" } )
> db.adminCommand( { addshard: "shard23/delta6:2423,delta5:2423", name: "shard23" } )
# SSD
> db.adminCommand( { addshard: "delta5:2424",name: "shard24" } )
# Enable Sharding
> db.adminCommand( { enablesharding : "mydb" } )
> db.adminCommand( { shardcollection : "mydb.log", key : { hour : 1 } } )"addshard" コマンドによってshardを構成していきます。"name"キーはそのshardの名前を決定し、"addshard"キーでshardの所在をhost名とport名により指定します。上記の例はReplica Setsを各Shardで構成しているためにReplica Setsメンバー全員の所在とSet名を指定しています。例えば"shard00"は"shard00"というSet名を持ったReplica Setsメンバー、delta1:2400とdelta2:2400(と後1つのarbiter server)を指定しています。またこのような24台のHDD上のReplica Setsを持つShardを構成するのに加えて、"shard0024"というReplicationを行っていない、かつSSD上に配置されたShardを登録しています。これは他のShardとは別の目的で用意しています。そして"enablesharding"コマンドによってデータベース"mydb"をSharding対象に加え、"mydb.log"コレクションをShard Key: "hour"で分割することを指定しています。実際に挿入されるレコード例を挙げておきます(一部加工済):
{
"_id" : ObjectId("4de3d6f573a4bc264f002619"),
"protocol" : "HTTP/1.1",
"hour" : 23,
"referer" : "-",
"ipaddr" : "000.00.000.000",
"responseBodySize" : 6052,
"userId" : "777777",
"timeMilliSec" : 83396000,
"options" : {
},
"userAgent" : "DoCoMo/2.0 F706i(c100;TB;W24H17)",
"params" : {
"count" : "10",
"opensocial_viewer_id" : "777777",
"material" : "1",
"item" : "61",
"opensocial_owner_id" : "777777",
"opensocial_app_id" : "10"
},
"time" : "23:09:56",
"date" : 20110530,
"path" : "/hoge/foo/bar",
"method" : "GET",
"statusCode" : "200"
}
メモリやCPUの優秀なマシンを割り降ることで初期段階のデータの局所集中に耐える
Sharding開始直後は1つのChunkからスタートします。これは1つのShardにデータが集中することを意味しています。特に初動から多数のアクセスが見込まれる場合、またはShard間でサーバースペックが異なる場合は、高性能マシンをPrimary Shardに割り当て、高い負荷に備える準備が必要です。Primary Shardの設定は上記のコマンドに続いて以下の様に行います。
> db.adminCommand( { moveprimary : "mydb", to : "shard24" } );
{ "_id" : "mydb", "partitioned" : true, "primary" : "shard24" }これによりPrimary Shardを意図的に"shard0024"に移動することができます。この設定を行わない場合は、自動でどこかのShardがPrimaryに設定されています。Primary Shardの設定はデータの挿入後にも行う事ができますが、エラーが出る可能性があること、事前に行うことに多くの意義を持つことに注意しておいて下さい。
Primary ShardはSSD上に配置し、Map Reduceなどの出力を高速に行う
今回の例の場合では、Primary Shard: shard24をこちらの目的で活用しています。shard24は解析専用サーバーのSSD上に配置されています。また、意図的な設定によって、このshard上には普通のデータは入って来ないようにしており、Map Reduceを使用した際の出力先のコレクションとしてのみ活用することにしています。複雑な集計作業においては、複数のMap Reduceの結果を用いてさらにMap Reduceを行うような場合がありますので、今回はその目的で高速な出力と、SSD上で多段MapReduceを高速に行うためのShardとして活用しています。例えば以下の様なUUを求めるMapReduceの結果はshard24上の"mr"コレクションに格納されます:
> m = function() { emit(this.userId, 1); }
> r = function(k,vals) { return 1; }
> res = db.log.mapReduce(m, r, { out : {replace:'mr'} });
{ "result" : "mr",
"shardCounts" : {
"shard00/delta1:2400,delta2:2400" : {
"input" : 11349174,
"emit" : 11349174,
"output" : 167265 },
"shard01/delta1:2401,delta2:2401" : {
"input" : 7582207,
"emit" : 7582207,
"output" : 139164 },
...
"shard23/delta5:2423,delta6:2423" : {
"input" : 7508581,
"emit" : 7508581,
"output" : 144319
}
},
"counts" : {
"emit" : NumberLong(174721895),
"input" : NumberLong(174721895),
"output" : NumberLong(3317670)
},
"ok" : 1,
"timeMillis" : 681401,
"timing" : {
"shards" : 653462,
"final" : 27938
},
}以上の結果の統計情報を見ても"shard24"はデータが存在せずに、集計対象から外れていることがわかります。それではmongosからではなく、shard24上のmongodに直接アクセスして、そこに"mr"コレクションがあるか覗いてみます:
$ mongo delta5:2424/mydb
MongoDB shell version: 1.8.1
connecting to: delta5:2424/mydb
> show collections
log
mr # mr コレクションが確かにshard24に存在
system.indexes
> db.mr.count()
500000
> db.mr.find()
{ "_id" : "u100001", "value" : 1 }
{ "_id" : "u100002", "value" : 1 }
{ "_id" : "u100003", "value" : 1 }
has more大量の出力がある場合や保存されたコレクションからさらに何らかの集計を行う場合には、Primary Shardを利用して特定の用途だけのShardを作るような方法は有効な手段となることでしょう。
2. Chunkの事前分割 〜運用開始からデータを分散させる〜
Primary Shardの話の中で、「初期段階では1つのShardにデータが集中する」問題を挙げましたが、これに対してはより効果的な対策を施す事が出来ます。設定したShardKeyに対してデータを挿入する前にChunkの分割を行ってしまおうというものです。これは事前にShardKeyの分布が予測できている場合には始めから均質なデータの分散を可能にすることができます。今回の例では(そこまで均質性を求める事はできませんが、)入ってくるデータ(ログレコード)が記録された時間(0〜23)をshardKeyにすることで、初動からデータを分散させるように意図しています。この作業はデータが挿入される前に行わなければならないことに注意して下さい。
db.adminCommand( { split : "mydb.log" , middle : { hour: 0 } )
db.adminCommand( { split : "mydb.log" , middle : { hour: 1 } )
...
db.adminCommand( { split : "mydb.log" , middle : { hour: 23 } )このsplitコマンドを実行する事によって、"middle"で定めたShardKeyの値を中心にしてChunkの分割を行ってくれます。今回はこれを0,..23のmiddle値でsplitコマンドを実行する事によって異なる時間のログレコードは異なるchunkに入るように設定しています。このコマンドを実行した結果を確認してみます:
> db.printShardingStatus()
{ "_id" : "mydb", "partitioned" : true, "primary" : "shard24" }
mydb.log chunks:
shard24 25
{ "hour" : { $minKey : 1 } } -->> { "hour" : 0 } on : shard0025 { "t" : 1000, "i" : 1 }
{ "hour" : 0 } -->> { "hour" : 1 } on : shard24 { "t" : 1000, "i" : 3 }
{ "hour" : 1 } -->> { "hour" : 2 } on : shard24 { "t" : 1000, "i" : 5 }
{ "hour" : 2 } -->> { "hour" : 3 } on : shard24 { "t" : 1000, "i" : 7 }
{ "hour" : 3 } -->> { "hour" : 4 } on : shard24 { "t" : 1000, "i" : 9 }
...
{ "hour" : 22 } -->> { "hour" : 23 } on : shard24 { "t" : 1000, "i" : 47 }
{ "hour" : 23 } -->> { "hour" : { $maxKey : 1 } } on : shard24 { "t" : 1000, "i" : 48 }この結果より、Chunkのレンジが (-∞, 0 ), [0, 1 ), [1, 2 ),..., [22, 23 ), [23, ∞ ) に分割されていることが確認できます。ここまででChunkの事前分割は実現しましたが、また異なるshardに分散させるところまでは実現していません。全ての行で"on : shard24"とあるように、全てのChunkは自動Balancing機能が働くまで、依然としてshard24上に集中して存在してしまうことになります。
3. Chunkの手動マイグレーション 〜安全に効率的にChunkを移動する〜
そこで次にChunkを意図的に移動(マイグレーション)させることにします。これを手動で行う事によって初動からデータを分散させることができ、かつChunkを置きたい場所に自由に移動させておくことで、データの意図的なルーティングも可能になります。
db.adminCommand({moveChunk : "mydb.log", find : {hour : 0}, to : "shard00"})
db.adminCommand({moveChunk : "mydb.log", find : {hour : 1}, to : "shard01"})
db.adminCommand({moveChunk : "mydb.log", find : {hour : 2}, to : "shard02"})
...
db.adminCommand({moveChunk : "mydb.log", find : {hour : 22}, to : "shard22"})
db.adminCommand({moveChunk : "mydb.log", find : {hour : 23}, to : "shard23"})この"moveChunk"コマンドは、findキーで指定したShardKey条件に該当するドキュメントを含むChunkをtoキーで指定したShardに移動させます。今回の例では、Chunk [ 0, 1 ) (つまりhour=0のデータ)をshard00に移動させています。この結果を見てみますと今度は、各Chunkが異なるShardに存在している事が確認できます。
> db.printShardingStatus()
{ "_id" : "mydb", "partitioned" : true, "primary" : "shard0025" }
mydb.log chunks:
shard24 1
shard00 1
shard01 1
shard02 1
...
shard22 1
shard23 1
{ "hour" : { $minKey : 1 } } -->> { "hour" : 0 } on : shard24 { "t" : 26000, "i" : 1 }
{ "hour" : 0 } -->> { "hour" : 1 } on : shard00 { "t" : 3000, "i" : 0 }
{ "hour" : 1 } -->> { "hour" : 2 } on : shard01 { "t" : 4000, "i" : 0 }
{ "hour" : 2 } -->> { "hour" : 3 } on : shard02 { "t" : 5000, "i" : 0 }
...
{ "hour" : 22 } -->> { "hour" : 23 } on : shard22 { "t" : 25000, "i" : 0 }
{ "hour" : 23 } -->> { "hour" : { $maxKey : 1 } } on : shard23 { "t" : 26000, "i" : 0 }この設定の元でデータの挿入を行った場合、データのhour値によってそれぞれのShardに始めから分散させて挿入することができます。実際に挿入して確かめてみましょう:
$ mongo delta1:2600/mydb #connect to mongos
> for( var n=0; n<24; n++ ){
... db.log.insert({"hour": n})
... }
$ mongo delta1:2400/mydb
> db.log.distinct("hour")
[ 0 ]
$ mongo delta1:2401/mydb
> db.log.distinct("hour")
[ 1 ]
...
$ mongo delta1:2423/mydb
> db.log.distinct("hour")
[ 23 ]意図したとおりの結果が得られている事が確認できました。この設定は非常に効果的ですので、一度検討してみて下さい。
4. Chunkの手動分割&マイグレーション 〜動かないChunkを移動する〜
すでにSharding環境を構築して運用されている場合でも、2.と3.でお話したことは実践が可能です。つまりあるShard内の、既にデータが詰まっているChunkを意図的に分割して軽くし、特定のShardへ移動させることが可能です。これらの作業は次の意味で非常に有用です:
・Shard間の偏りを自力で補正する
・類似のChunkを同じShardへ集合させることでデータローカリティを実現する
shard間の偏りを自力で補正する
MongoDBの自動Balancing機能ではShard間の偏りがどうしても生じてきてしまいます。実際のChunkのマイグレーションには、そのChunkサイズと同じ以上のメモリ領域と、configサーバーへの大きな負担をかけるというリスクによって、必ずしも成功するとは限りません。メモリが足りなければChunkの移動が必要な状況でも決して起こりません。これらの状況は避けることができませんので、手動でのChunkの移動を定期的に行うようにします。また、Chunkサイズが大きかったりメモリが足りなくて移動に失敗する場合は、Chunkの手動分割によってより細かいサイズまで分割してから移動させることにします。まずはShardごとのデータサイズを確認して、Chunkの手動分割・移動を行ってみます:
> printShardingSizes()
...
{ "_id" : "mydb", "partitioned" : true, "primary" : "shard24" }
mydb.log chunks:
{ "hour" : { $minKey : 1 } } -->> { "hour" : 0 } on : shard24 { "size" : 0, "numObjects" : 0 }
{ "hour" : 0 } -->> { "hour" : 1 } on : shard00 { "estimate" : false, "size" : 89590388, "numObjects" : 198518 }
{ "hour" : 1 } -->> { "hour" : 2 } on : shard01 { "estimate" : false, "size" : 75265412, "numObjects" : 165859 }
{ "hour" : 2 } -->> { "hour" : 3 } on : shard02 { "estimate" : false, "size" : 163306000, "numObjects" : 360413 }
...
{ "hour" : 22 } -->> { "hour" : 23 } on : shard22 {"estimate" : false, "size" : 254483548, "numObjects" : 576126 }
{ "hour" : 23 } -->> { "hour" : { $maxKey : 1 } } on : shard23 { "estimate" : false, "size" : 247971184, "numObjects" : 561015 }
このコマンドによって各Shardの各データベース/コレクションのデータサイズ(の推定値)とオブジェクト数を確認することができます。他にも各Shard情報を確認するコマンドがあります。実際の分割・移動は前回までにお話したことと同じですが、分割に関しては、既にデータが存在しているので、対象のChunkをfindキーで特定して等分割を行う事にします(前回はmiddleキーだったことに注意して下さい)。今までの例はhourという24種類しかないキーをShardKeyに設定してしまっているため、分割などをしにくい状態になってしまっています。ここでは00:00:00を0としたtimeMilliSecをShardKeyとしている前提で分割することにします。
> db.adminCommand( { split : "mydb.log" , find : { timeMilliSec : 60000 } } ) このコマンドによってtimeMilliSecキー: 60000 を含むChunkが等分割になるようなキーで分割が行われます。Chunkの移動の方は前回お話したコマンドと全く同じです:
db.adminCommand({moveChunk : "mydb.log", find : {timeMillSec : 30000}, to : "shard10"})これによって分割した片方の、timeMillSec=30000を含む方のChunkをsahrd10に移動させる事ができました。
類似のchunkを同じShardへ集合させることでデータローカリティを実現する
後の解析を見据えた場合のデータストレージにおいては、データの分散を意識しつつ、データローカリティ、つまり類似のデータは同じShardに存在させておいて検索や集計の効率性を上げることも意識しておく必要があります。完全にデータローカリティに特化したストレージを行うには、類似のChunkを特定のShardに集合させるようにします。この場合はShardの偏りはあまり気にしないでしょう。
5. Shardの状態を監視する 〜有用な2つのコマンド〜
さて、最後になりましたが、ここまでに登場したSharding環境で頻繁に使うことになるコマンドを紹介しておきます。
printShardingStatus(undefined,true)
機能的には db.printShardingStatus() と同じなのですが、 db.printShardingStatus() で肝心のChunkの分割情報を表示してくれない状況が発生してきます:
> db.printShardingStatus()
...
shard0022 1
shard0023 1
too many chunksn to print, use verbose if you want to force print #肝心な情報が見れない…orzその場合に printShardingStatus(undefined,true) を使います:
> printShardingStatus(undefined,true)
...
shard0022 1
shard0023 1
{ "hour" : { $minKey : 1 } } -->> { "hour" : 0 } on : shard0025 { "t" : 26000, "i" : 1 }
{ "hour" : 0 } -->> { "hour" : 1 } on : shard0000 { "t" : 3000, "i" : 0 }
{ "hour" : 1 } -->> { "hour" : 2 } on : shard0001 { "t" : 4000, "i" : 0 }
...また、Chunkの情報はconfigデータベースからも確認することができます:
>use config
> db.chunks.find().forEach(printjson)
...
{
"_id" : "mydb.log-hour_22.0",
"lastmod" : {
"t" : 25000,
"i" : 0
},
"ns" : "mydb.log",
"min" : {
"hour" : 22
},
"max" : {
"hour" : 23
},
"shard" : "shard22"
}
{
"_id" : "mydb.log-hour_23.0",
"lastmod" : {
"t" : 26000,
"i" : 0
},
"ns" : "mydb.log",
"min" : {
"hour" : 23
},
"max" : {
"hour" : { $maxKey : 1 }
},
"shard" : "shard23"
}configデータベースにはその他Shardingに必要なメタ情報を管理していますのでここから様々な情報を取得することが可能です。ただし、このメタ情報をupdateしたりremoveしたりすると大変な事になるので注意して下さい。configサーバーで手を加えて良いのは自動Balancing機能をオフにする場合だけです:
use config
db.settings.update( { _id: "balancer" }, { $set : { stopped: true } } , true )
printShardingSizes()
こちらも既出ですが、各Shardのデータサイズとオブジェクト数をコレクションごとに表示してくれる便利なコマンドです。ただし、このコマンドがデータ数が多くなると返ってくるのが非常に遅くなってしまいます。その場合には他のコマンドで確認するようにしてください。
> printShardingSizes()
Wed Jun 1 00:30:46 updated set (shard00) to: shard00/delta1:2400,delta2:2400
Wed Jun 1 00:30:46 [ReplicaSetMonitorWatcher] starting
...
--- Sharding Status ---
sharding version: { "_id" : 1, "version" : 3 }
shards:
{ "_id" : "shard0000", "host" : "shard00/delta1:2400,delta2:2400" }
{ "_id" : "shard0001", "host" : "shard01/delta1:2401,delta2:2401" }
{ "_id" : "shard0002", "host" : "shard02/delta1:2402,delta2:2402" }
...
playshop-gree-access.log chunks:
{ "hour" : { $minKey : 1 }, "date" : { $minKey : 1 } } -->> { "hour" : 0, "date" : { "$minKey" : 1 } } on : shard0012 { "estimate" : false, "size" : 1854702464, "numObjects" : 3765808 }
{ "hour" : 0, "date" : { "$minKey" : 1 } } -->> { "hour" : 1, "date" : { "$minKey" : 1 } } on : shard0013 { "estimate" : false, "size" : 1384094100, "numObjects" : 2806727 }
{ "hour" : 1, "date" : { "$minKey" : 1 } } -->> { "hour" : 2, "date" : { "$minKey" : 1 } } on : shard0014 { "estimate" : false, "size" : 882130544, "numObjects" : 1780488 }
{ "hour" : 2, "date" : { "$minKey" : 1 } } -->> { "hour" : 3, "date" : { "$minKey" : 1 } } on : shard0015 { "estimate" : false, "size" : 539366856, "numObjects" : 1089989 }
{ "hour" : 3, "date" : { "$minKey" : 1 } } -->> { "hour" : 4, "date" : { "$minKey" : 1 } } on : shard0016 { "estimate" : false, "size" : 419811240, "numObjects" : 848770 }
{ "hour" : 4, "date" : { "$minKey" : 1 } } -->> { "hour" : 5, "date" : { "$minKey" : 1 } } on : shard0017 { "estimate" : false, "size" : 726579776, "numObjects" : 1471823 }
{ "hour" : 5, "date" : { "$minKey" : 1 } } -->> { "hour" : 6, "date" : { "$minKey" : 1 } } on : shard0018 { "estimate" : false, "size" : 1152177872, "numObjects" : 2347418 }
{ "hour" : 6, "date" : { "$minKey" : 1 } } -->> { "hour" : 7, "date" : { "$minKey" : 1 } } on : shard0019 { "estimate" : false, "size" : 2630525884, "numObjects" : 5485197 }
{ "hour" : 7, "date" : { "$minKey" : 1 } } -->> { "hour" : 8, "date" : { "$minKey" : 1 } } on : shard0020 { "estimate" : false, "size" : 5387886924, "numObjects" : 11132989 }
{ "hour" : 8, "date" : { "$minKey" : 1 } } -->> { "hour" : 9, "date" : { "$minKey" : 1 } } on : shard0021 { "estimate" : false, "size" : 2379915544, "numObjects" : 4840048 }
{ "hour" : 9, "date" : { "$minKey" : 1 } } -->> { "hour" : 10, "date" : { "$minKey" : 1 } } on : shard0022 { "estimate" : false, "size" : 2308302612, "numObjects" : 4689784 }
{ "hour" : 10, "date" : { "$minKey" : 1 } } -->> { "hour" : 11, "date" : { "$minKey" : 1 } } on : shard0023 { "estimate" : false, "size" : 2558705640, "numObjects" : 5189979 }
{ "hour" : 11, "date" : { "$minKey" : 1 } } -->> { "hour" : 12, "date" : { "$minKey" : 1 } } on : shard0000 { "estimate" : false, "size" : 1881322140, "numObjects" : 3818884 }
{ "hour" : 12, "date" : { "$minKey" : 1 } } -->> { "hour" : 13, "date" : { "$minKey" : 1 } } on : shard0001 { "estimate" : false, "size" : 2264673264, "numObjects" : 4605082 }
{ "hour" : 13, "date" : { "$minKey" : 1 } } -->> { "hour" : 14, "date" : { "$minKey" : 1 } } on : shard0002 { "estimate" : false, "size" : 2303920996, "numObjects" : 4686648 }
{ "hour" : 14, "date" : { "$minKey" : 1 } } -->> { "hour" : 15, "date" : { "$minKey" : 1 } } on : shard0003 { "estimate" : false, "size" : 3298773252, "numObjects" : 6840413 }
{ "hour" : 15, "date" : { "$minKey" : 1 } } -->> { "hour" : 16, "date" : { "$minKey" : 1 } } on : shard0004 { "estimate" : false, "size" : 3157248456, "numObjects" : 6542235 }
{ "hour" : 16, "date" : { "$minKey" : 1 } } -->> { "hour" : 17, "date" : { "$minKey" : 1 } } on : shard0005 { "estimate" : false, "size" : 2521432232, "numObjects" : 5130008 }
{ "hour" : 17, "date" : { "$minKey" : 1 } } -->> { "hour" : 18, "date" : { "$minKey" : 1 } } on : shard0006 { "estimate" : false, "size" : 2551743308, "numObjects" : 5197201 }
{ "hour" : 18, "date" : { "$minKey" : 1 } } -->> { "hour" : 19, "date" : { "$minKey" : 1 } } on : shard0007 { "estimate" : false, "size" : 1840064336, "numObjects" : 3695385 }
{ "hour" : 19, "date" : { "$minKey" : 1 } } -->> { "hour" : 20, "date" : { "$minKey" : 1 } } on : shard0008 { "estimate" : false, "size" : 2250083536, "numObjects" : 4526531 }
{ "hour" : 20, "date" : { "$minKey" : 1 } } -->> { "hour" : 21, "date" : { "$minKey" : 1 } } on : shard0009 { "estimate" : false, "size" : 2556930488, "numObjects" : 5139566 }
{ "hour" : 21, "date" : { "$minKey" : 1 } } -->> { "hour" : 22, "date" : { "$minKey" : 1 } } on : shard0010 { "estimate" : false, "size" : 2567556160, "numObjects" : 5295961 }
{ "hour" : 22, "date" : { "$minKey" : 1 } } -->> { "hour" : 23, "date" : { "$minKey" : 1 } } on : shard0011 { "estimate" : false, "size" : 2323384656, "numObjects" : 4784284 }
{ "hour" : 23, "date" : { "$minKey" : 1 } } -->> { "hour" : { $maxKey : 1 }, "date" : { $maxKey : 1 } } on : shard0023 { "estimate" : false, "size" : 0, "numObjects" : 0 }
...
まとめ
いかがでしたでしょうか?今回は内容がマニアックすぎたので何を言っているのかわからなかった方も多いと思います。実際にSharding環境を構築されて、同じような問題や必要に迫られたときに、もう一度この記事を思い返して頂ければ幸いです。
弊社の新解析基盤も今日お話した設定を反映しながら、26Shard+Replica Sets、データサイズ18TB×2 の規模で運用を開始しています。ここに述べたことだけでなく、自動Shardingや自動Balancingを行わないマニュアルのChunk分割ルールやShardの世代管理、SlaveからもMap Reduceを同時に行ったりHadoopやRedisと連携する集計方法など、色々やっています。またその辺の話も安定して運用できるようになればお話できればと思っています。
今後ともMongoDBを宜しくお願いします。
「ニフティクラウドでMongoDBは使えるか?」を読んで、僕なりの考察を書いてみた
@doryokujinです。2011年5月19日付けのニフティクラウドさんのブログエントリーが「ニフティクラウドでMongoDBは使えるか?」と称してニフティクラウド上でMongoDBのパフォーマンス比較を行うという、非常に興味深いものでしたので、このエントリーを読んで僕なりの考察をまとめてみました。完全な検証環境がわからないので一部推測を含み、誤解などもあるかもしれませんが、それらのフィードバックも期待して、ブログにすることにしました。ですのでまずはこのエントリーを読んで下さいね。
ニフティクラウドでMongoDBは使えるか? : NIFTY Cloud ユーザーブログ
それではエントリーの中盤、「Benchmark」以降を部分的に引用しながら考察を述べていきたいと思います。
shardKeyを考慮に入れる事の重要性
■ Benchmark 下記のような条件およびプロセスでベンチマークを行い、プロセス完了までの時間を計測しました。
データ twitterのtweetを1.4GB (delete含めて707,259tweet)
条件
・shardingの有無(1台=無 vs. 3台)
・stripingの有無(有 vs. 無)
・ニフティクラウドスペック(mini vs large16)
まず提示された条件については、以下の情報が不足しているように感じました。
shardingを構成する際に、shardKeyとして何を設定したか?
MongoDB のshardingでは、1番始めに行う「shardKeyの設定」が非常に重要です。このshardKeyの設定次第では、shard間の偏りやデータの非効率な取得が生じてしまう原因になります。また、find()やinsert()などの処理に関してもそのshardKeyを条件に含めて実行するかどうかで効率性が大きく異なってきます。shard環境の有無でfind()やinsert()の性能比較を行う場合には、shardKeyを条件に含めた場合と含めない場合の両方でさらに比較する必要があります。このshardKeyが不明ですとこの切り分けができません。
ここでは前提としてstatus_idをshardKeyにすることにします
今回のインプットはTwitterデータということで、最も一般的なstatus_idをshardKeyにした場合で考えることにします。実はstatus_idはMongoDBのshardKeyを考える上で非常に良い例となってくれます(最後のスライドの2枚目をご覧下さい)。
ここでのstatus_idは時間増加する性質をもったものと仮定しています。つまり時間が進みにつれてstatus_idが単調増加する性質です。一時期Cassandraを採用するためにこのstatus_idが時間増加にならないようにするといった話題が出ましたが、Cassandraを採用しなかった今、結局どうなったのでしょうか…(^_^;)
find() の条件にshardKeyを含むか否か、キーにインデックスを作成しているか否かの切り分けは比較としてとても重要なファクターです
プロセス
...
find
コレクションからデータを取得するコマンドです。MongoDBの場合は、ドキュメントを縦横無尽に条件付けてフィルタリングができるのでこの性能も無視できない重要な性能です。・1条件 find({source:'web'})
・ネスト条件 find({'user.lang':'ja'})
・否定 find({'geo':{$ne:null}})
・サイズ find({'entities.hashtags:{$size:2}})
・比較 find({'retweet_cnt':{$gt:1}})
MongoDBのパフォーマンス比較においては、これらのfindの条件が
- shardKey を含むかどうか
- インデックスを作成しているかどうか
を明示的に考慮に入れた方が良いと感じます。
検索条件にshardKeyが含まれている場合とそうでない場合
まず前者について考えていきます。sharding環境のfind()においては、その条件にshardKeyを含ませるか否かでデータ取得の方法が異なってきます。shardKeyが含まれている場合、mongosは該当のshardKeyを持つshardがどこにあるのかを知っていますので、そのshardにだけクエリを実行することができます。

逆に、shardKeyを含まない場合にはmongosは全てのshardに対してクエリを実行して取得したデータをマージしてクライアントに返してくれます。

つまりsharding環境において効率の良いクエリが実行できるのは、find()の条件にshardKeyが含まれていた場合です。ですので性能比較の際にはshardKeyを含ませるかどうかの違いも検証することが重要です。
(余談)mapreduce はcount()やdistinct()との比較もあれば
mapreduce
MongoDBを十二分に活用するのであれば、避けられないコマンドです。簡単な解析に利用することが出来ます(簡単、と書きましたがかなり使えます)。
・単純なグループ集計(source集計)
・単純なグループ集計(5分ごとのtweet数集計)
・2条件のグループ集計(1時間当たり・1人当たりのtweet数集計)
・少し複雑な集計(1時間当たりのhashtag集計)
・少し複雑な集計(共起するhashtag集計)
count() や distinct() は高速
余談ですが、sharding環境でのMongoDBにおけるmapreduceの比較については、単純なmapreduceを記述する場合にはcount()やdistinct()といった組み込み関数との比較を行うのも面白いと思います。例えばtweet数集計や、sourceの集計、あるいはUUの計算などはsharding環境でもcount()やdinstinct()コマンドが全shardを対象に行ってくれます(正しい値を返さない場合もありますが…)。そしてこれらは実はmapreduceよりも高速に結果を返してくれます。例えば24shard環境で130GB、1億2千万レコードのuseridが特定できているアクセスログに対してUU計算を行った場合、mapreduceで記述した場合が350secに対してdistinct()を用いた場合には200secでした。これは後者がインデックスを利用して効率良く集計くれているからだと思います。
結果に対する考察
それではエントリーに記述されたベンチマーク条件での比較結果について、今まで述べた性質を考慮しながら考察してみたいと思います。
| スペック | mini | large16 | ||||||
|---|---|---|---|---|---|---|---|---|
| sharding | 無 | 有 | 無 | 有 | ||||
| striping | 無 | 有 | 無 | 有 | 無 | 有 | 無 | 有 |
| mongoimport | 549.201 | 520.438 | 630.101 | 690.042 | 259.671 | 104.757 | 263.050 | 193.803 |
| find | 38.378 | 42.293 | 13.618 | 14.998 | 1.044 | 1.030 | 1.124 | 1.132 |
| mapreduce | 226.64 | 229.46 | 107.39 | 106.85 | 52.53 | 52.10 | 26.08 | 26.08 |
全体
全体的にざっくりと見ると、当然といえば当然ですが、VMのスペックがimport/find/mapreduceに大きなパフォーマンスの差に影響を及ぼしています。
また、IO性能に関わるstripingに関しては、import、特にlarge16以外ではほとんど意味のある効果を発揮していませんでした。これはminiの場合はIOよりもmemory/cpuがボトルネックになっているためだと考えられます。データサイズが1.4GBであるため、mini(memory=512MB)においてはfindやmapreduceにおいてIO性能の及ぼす影響が強いと予想していましたが、ほとんど見られませんでした。これは今後追求していければと思っています。
findに関しては検索に使用したキーにインデックスを使用していたかがポイントになってくるような気がしました。mapreduceに関しては基本的にドキュメント全件走査しますが、findの場合はインデックスが使用できますので作成しているキーが条件に指定された場合には全件走査をする必要がありません。インデックスを作成した場合とそうで無い場合でもボトルネックはmemory/cpuであったのかも試されると良かったのかもしれません。(恐らく同じボトルネックであったと思いますが。)
また、インデックスを作成した場合、MongoDBはインデックスサイズが大きくなりやすい傾向があります。今回の場合、miniインスタンスでさらにインデックス作成の有無でさらに比較をしたとすると、findにインデックスを作成することの高速化する一方で、大量のメモリ消費の影響がどのくらいありそうなのかが気になりました。
mongos
上記と重複しますが、スペックにおける影響が非常に強く、また、次に、large16のときにstripingの影響が出ていました。このimport処理では書き込み性能に影響が出るため、shardingの影響を予測していましたが、shardingによる性能の改善は見られないばかりか、1台で行った場合よりも劣化するという結果でした。
sharding環境の有無でmongoimportに差が出なかったのは恐らくshardKeyの問題ではないでしょうか。前述しましたが、shardingは事前に設定したshardKeyに従ってデータを各shardに分割しています。例えばこのshardKeyの値が "_id" を始めとした時間軸に対して増加するキーであった場合には、連続して挿入されるデータは分散されずに同じchunk、つまり同じshardに入ってしまいます。この場合にはshardingしていながら、実際にはシングルサーバーへ書き込みを行っているのと同じ、さらにはmongosサーバーを介することによってシングルよりも無駄なステップを消費しています。今回の結果の原因は、status_idをshardKeyとして使用しているような場合にはこれによるものと考えられそうです。
この結果は、mongosまたはconfigサーバがボトルネックとなりうるという要因が予測されます。今後、例えばmongosを分割し、それぞれに対して同時にimportを行い、全体としてのパフォーマンスの改善が見られるかを検討する必要があるかと思います。
mongosもconfigサーバーもそれほど負荷のかかる役割を担う処理を行いませんし、複数用意するのは主にレプリケーション目的であって、スケール目的ではありません。ですのでこれらはボトルネックにはなりにくいはずです。
ただ、一度に大量なインサートを行う場合には、mongosを複数用意してデータを分割して、各mongosに並列insertすることによって多少の負荷を軽減することができそうですし、書き込みにゆとりがある場合には並列insertの方が高速に処理してくれそうです。
また、クライアントとのデータ入出力の窓口を増やすことで1つのmongosがダウンしてしまった際にも安定稼働させる上で有用だと思います。
find
IO性能に関わるstripingはほぼ、findにおいては影響を見せませんでした。またshardingによるfindの性能は、miniでは、およそ2倍?3倍程度の改善を示していましたが、large16ではほとんど効果が見られませんでした。同時に、stripingも影響があまり見られませんでした。
今回の程度のデータサイズであれば、cpu/memory性能が十分に高ければ分散させてIO性能を稼ぐことにあまり意義が無いと考えられます。
find処理においては、検索条件にshardKeyが含まれていたかどうかが重要になります。もしshardKeyが検索条件に含まれていた場合には、mongosはどのshardに該当するデータが存在するかを把握していますので必要なshardに対してのみ検索を行うので効率良く高速に実行できます。しかし、shardKeyが検索条件に含まれていない場合は、全てのshardにfind()を実行し、結果をマージするということを行いますので効率があまりよくありません。
今回差が出なかったのも検索条件にshardKeyが含まれていなかったので全部のshardを確認していったからでは無いでしょうか?
(もちろん、全てのクエリがいつもshardKeyを含んでいるとは限りません、MongoDBはメモリをうまく利用することによって、この場合でもそれなりに速く実行してくれます。)
あるいはsharding環境においては、バックグラウンドでchunkのマイグレーションが行われているかどうかによってパフォーマンスが変わってきます。chunkのマイグレーション中はデータの移動がバックグラウンドで行われており、その際にchunkは丸々メモリにコピーされています。マイグレーションが行われている場合にはこのメモリの消費とサーバーへの負担のせいでパフォーマンスが一時的に下がってしまう可能性があります。
ただ、今回はその状況は起きていないと考えられます。デフォルトのchunkサイズは200MBであり、balancing機能によってマイグレーションが発動するタイミングは、現在アクセスされているshardのchunk数と、最もchunk数の少ないshardとの数の差違で10以上になったときです。すなわち2GB以上の差違が生じた時に発動します。今回のデータは1.4GB、MongoDBに格納した場合に2.5GB程度になると考えられますのでそもそもマイグレーションが発生していたかどうか、またそれが起きたとしても少ないマイグレーション回数でbalancingできるので、検証実行時には既にそのマイグレーションが完了しており、その状況に出くわさなかったことが考えられます。
それでは、なぜminiではshard環境の有無で結果に差が出たかというと、はやりシングルサーバーの場合はmemory/cpuがボトルネックになっていて、それが3つのmemory/cpuにデータを分散できたことで解消されたので、shardKeyが条件指定されておらず、全部のshardを見に行くという処理になっても高速に実行できたのではないでしょうか?
mapreduce
今回、一番ベンチマークを取った甲斐があるプロセスでした。stripingについては性能にほとんど影響が見られませんでしたが、shardingの効果がよく出ており、簡単とはいえ集計や計算がcpu/memory依存で行われ、mapreduceを複数台で実現することの意味が見出せたものと考えられます。
map/reduceに関してはsharding環境を活用できますので高速化が最も期待できるところです。ただし、ここでもshardKeyの設定によって、集計対象とするデータが1つのshardに偏っている場合などは、その効果があまり期待できません。
また、map/reduceの実行は基本的に1shardあたり1スレッドしか使えません。このことは例えば8coreと1coreのCPUをそれぞれ積んだサーバーで比較しても、1サーバーごとに1shardしか配置されていない場合には大きな差違が出ないということです。
MongoDBのmapreduceはshuffle機能が無いなど、Hadoop等のmapreduceに比べてやや簡素化された仕組みでありますが、この1core/shard制約は最も大きな違いであり、MongoDBのmapreduceがスケールしない、遅いといわれているゆえんであります。
これらを考慮して、データの均等分散に気を遣い、かつコア数だけshardを同居させるといった(これは非推奨です)環境で実行した場合にはより大きな差を生むことが出来るはずです。

mapreduceの特性を理解して環境を構築する重要性
今回、すべてのデータについては、分散はほとんど見られなかったこともあり、ざっくりとした考察だけを行っていますが、いかがでしたでしょうか。実際に使う上でshardingを適切に配置し「Largeシリーズ」を使っていただければ。「Largeシリーズ」を使っていただければ、性能がスケールすることも含め、比較的性能的にもよいパフォーマンスが得られたのではないかと思っております。
1つのサーバーに1shardしか組まないという安全性を重視した設計を行う場合は、例えばメモリが4MBと同じでCPUのコア数のみが異なる「large」と「small4」ならばsmall4を選択してもそれほど問題が無いと思われます。しかしその金額の差違は、月額プランにして1サーバーあたり¥48,300-¥25,410=¥22,980。仮に10台のshardとそのreplicationとしてさらに10台を使用する場合には、月額で ¥22,980 × 20台 = ¥457,800 になります。このようにMongoDBのmapreduceの特性を理解せずに高スペックマシンの方が高速に動作すると思い込んで毎月数十万を無駄する可能性があります。
ニフティクラウドのインスタンス毎の金額設定は以下を参照して下さい:
クラウド 料金 | ニフティクラウド
逆に、あくまで試験的ですが、フルコアを使いきるためにlargeの4コアサーバーに擬似的に4shard構成にすることも可能です。この場合には必要なサーバー台数が1/4にできる一方で、月額は2倍高いだけなので、結果的にsmall4に比べて1/2の金額で済む事になります。ただ、これはmapreduceのみを考慮した話であり、同サーバーでその他の処理も行われていたりする場合などで状況は変わってくるので注意して下さい。
感想
まず、ニフティさん、エントリーに対して少し批判的な内容を含む記事になってしまったことをお詫びいたします。また、誤解や間違いもあるかもしれませんので、その際は指摘して頂けると幸いです。
今回の感想ですが、サービス提供側が、今回のような比較記事を積極的に示してくれることによって、そこから僕たちは非常にたくさんの情報を読み取ることができますので、非常に良いエントリーだと思いました。是非とも今後の継続的なレポートも期待しています。
また、ニフティクラウドを代表するクラウドサービスでMongoDBをメインに使用する環境を構築する場合には、MongoDBの特性を十分に考慮した上で構築しないと、無駄に高い構成になってしまったり、きちんとMongoDBを設定・チューニングできていないことによる低パフォーマンスをスペックのせいにして高スペックプランに乗り換えてしまうといった事態が生じてしまいがちです。十分に注意して下さい。
僕はクラウド上でMongoDBを活用してサービスや解析を展開される方を心より応援しています。気軽に声を掛けて下さい。そしてニフティさん、僕にクラウド環境を貸して頂ければMongoDBの性能検証などを詳細に行うことが可能です。いかがでしょうか?
※最後の最後に、shardKeyは重要ですという話をしましたので、悪いshardKey3例と良いshardKey1例を挙げておきます。




{kind=link}
〜うまく動かすMongoDB〜仕組みや挙動を理解する
@doryokujinです。この業界で非常に強い影響力を持つ@kuwa_tw氏が某勉強会でMongoDBについてdisられており、このままではMongoDB自身の存続が危ういと思い、急遽ブログ書きました。(冗談ですよ)
ザ・ドキュメント〜うまくいかないNoSQL〜
View more presentations from Akihiro Kuwano
MongoDBを使っているときに出会うトラブルをうまくまとめてくださった「MongoDBあるある」的な良い資料だと思います。今日はここで書かれているトラブルの解決方法を提示したいと思います。恐らく@kuwa_tw氏は全ての解決方法を知っていながら、同じトラブルへ悩む人のためにあえてdisったのだと思います。
MongoDB はデータベースもコレクションも存在しなければ自動作成してくれる

mongoシェルを起動する場合、たいていは
$ mongo
:
# mongo localhost:27017
のようにして現在稼働しているmongodのホスト名とポート名を指定してmongoシェル起動するかと思います。この時僕たちは既に「test」データベースの下にいることになります。そしてMongoDBは存在しないコレクション名に対してinsertを実行した場合はコレクションを作成してその中にドキュメントをinsertしてくれるのです。以下のコマンドを試して見てください。
$ mongo localhost:27017
MongoDB shell version: 1.6.4
connecting to: name1:27017/test> show collections # 現在のデータベースに存在するコレクションを確認
system.indexes> db.test.insert( {test: 1} ) # 存在しないはずのtestコレクションにドキュメント {test: 1} を挿入!
> show collections # testコレクションが作成されている
system.indexes
test
> db.test.find() # testコレクション内のデータ(ドキュメント)を確認
{ "_id" : ObjectId("4dd3ca8e0901112f237b9495"), "test" : 1 }
さらにMongoDBは存在しないデータベースに対しても処理を行うことができます。
> show dbs # 現在存在するデータベースを確認
admin
test> use newdatabase # 存在しないnewdatabaseデータベースに移ってみます
switched to db newdatabase> db.test.insert( {test: 1} ) # さらに存在しないはずのtestコレクションにドキュメント {test: 1} を挿入!
> show dbs #newdatabaseデータベースができている!
admin
newdatabase
test> show collections #testコレクションもできている!
test
system.indexes> db.test.find() # そしてデータも入っている
{ "_id" : ObjectId("4dd3cc1c0901112f237b9496"), "test" : 1 }
MongoDBは非常におせっかいなDBなのでこちらの怠惰な操作に関しても自動で色々と面倒を見てくれるのです。ここでのまとめは、
・mongo
: で起動した場合、testデータベースにいる。始めから移動しておきたいときは mongo : / とする
・存在しないデータベース、コレクションに対しても自動作成してinsertなどの処理が行える。エラーや警告は基本的に返さない
注意してください。
Replication時の親切な自動リカバリ機能
MongoDBのReplicationは非常にステキな機能を備えています。この機能の完成度は(他の機能に比べて)高い方だと思います。よく自動フェイルオーバーしないという話を聞きますが、きちんと設定とフェイルオーバーの仕組みを理解しておけば問題なく動作する(はず)です。今回@kuwa_tw氏に起こった問題を考えてみましょう。


MongoDBのReplica SetはSetメンバーを他のReplica Setと区別をつけるための
その後、ダウンしていた元Primaryサーバーを修復して、データを全部消して再起動したのが2枚目の図です。ここでのポイントは前回と同じホスト名・ポート名で再起動したことです。そうするとmongodを再起動した時点ですぐに現Primaryとの同期が始まり、できるだけ速く完全に同期がとれるように"Catch Up"してくれます。mongoを立ち上げてデータベースを確認したときには既に同期が完了していたということです。これをMongoDBの「自動リカバリ機能」と呼びます。自動フェイルオーバー時の挙動や自動リカバリについては以下の図を参考にしてください。





ちなみに異なるホスト名やポート名でmongodを起動した場合はこの自動リカバリ機能は発動しません。まずは手動でReplica Setsのメンバーに新しく加える作業を行わなければなりません。ここでの注意は、あまりにもデータが大きい場合や、oplogと呼ばれるコレクションのサイズを小さく設定した場合には、完全な同期を行うことができないので注意してください。MongoDBの同期はPrimrayのoplogに保存されている過去のオペレーションリストをSecondaryメンバーが自身のoplogにコピーして実行することによって行われます。また、このoplogは容量以上のオペレーションを保存しなければならなくなった場合には古いオペレーションをどんどん削除していきます。まっさらなメンバーをReplica Setsのメンバーに加えようとした場合、もしPrimary(または他のSecondaryメンバー)に全てのオペレーションが残っていないと、完全な同期が不可能になりますのでエラーになります。この場合はmongodumpなどの他の手段をとって同期を行うしかありません。
チャンクが移動しまくる・デフォルトのチャンクが大きすぎる

MongoDBにはShardingとよばれるデータを複数のサーバーに分割する機能を備えています。その機能と特徴は下の図を見てください。


MongoDBのShardingは2つのおせっかいな便利な自動機能をもっています。「自動Sharding」と「自動Balancing」機能です。前者はデータの振り分けルールを自動で行ってくれる機能で、始めに「Shard Key」と呼ばれる”どのキーの値によって分割ルールを定めるのか”を指定してさえおけば、後はMongoDBの方で自動的にそのキーで振り分けルールを決めてくれます。しかもデータが入ってくるごとにどんどんとそのルールを変更(細かくしていく)していってくれます。後者はShard間でのデータ偏りが大きくなった場合に、データの移動(マイグレーション)をバックグラウンドで自動で行ってくれる機能です。移動の単位はChunk単位です。この機能によってShard間でデータが均質になるようにMongoDBが頑張ってくれているのです。
自動Sharding
例えばShard Keyに"name"を指定したとします。すると始めはざっくりと「ア行はShard0」に「カ行はShard1」といった具合に振り分けルールを決定します。この「ア行に属するデータ集合」のことをChunk呼びます。各ChunkはShard Keyの値に対して他とかぶらない範囲をもっておりその範囲に属するデータはそのChunkの中に入っていきます。そしてChunkの中にデータが詰まりすぎた場合はそのChunkを等分割してChunkサイズを均等に保とうとします。先ほどの例でいうと、[あ,い,う,え,お]の範囲を持っていたChunkが[あ,い,う]と[え,お]というChunkに分割されます。@kuwa_tw氏が触れているデフォルトのChunkサイズは200MBです。つまり200MB以上のデータがそのChunk内に入ってきた場合に分割が行われることになります。データが大量に入ってきている状態の裏で、Chunkの細胞分裂が絶えず行われているのです。
実はデフォルトのChunkサイズは200MBなのですが、Sharding開始時では64MBに下げられています。そしてある程度のデータサイズとなった場合に200MBに変更されます(変更されないという話も聞きますが…)。もちろんこのデフォルトのChunkサイズは変更を行うことができます。mongosを起動するときにオプションとして --chunkSize [MB] を設定してやれば良いのです。
mongos --port 10000 --configdb host1:10001 --chunkSize 500
ここで --chunkSizeを1[MB]に設定してやるとchunkはデフォルトよりも遙かに速いペースで分割されていきます。ただ分割されるといっても、物理的な分割が行われているわけではないことに注意してください。しかしchunkSizeを1に設定すると後述するChunkの移動が絶えず行われるような状態に陥り、様々な問題を引き起こすので注意してください。



自動Balancing
ShardKeyを適切に設定しなかったり、大量のデータ挿入で振り分けルールの設定が追いつかなかった場合にはShard間でデータの偏りが生じてしまいます。これはどう頑張っても避けられない問題でもあります。しかしMongoDBはデータの偏りがある程度大きくなった時点で偏りの大きいShardから少ないShardへChunkの移動を行うことによってそれに立ち向かってくれます。しかも自動で。


Sharding の種々の問題
しかしこれらの機能が完璧に働いてくれることを期待してはいけません。MongoDBは多機能ですが、高性能ではありません。おせっかいですがたくさんドジをします。以下に起こりうる問題の一部をあげました。



@kuwa_tw氏の嘆かれている「チャンクが移動しまくる」という問題は、「チャンクのデフォルトサイズがでかい」と矛盾するのですが、チャンクサイズを大きくすれば移動しにくくなります。ただし、chunkの移動時にはそのchunkをまるまるメモリに乗っけるので、そもそもメモリに移動させるだけの空き領域がなければ移動が行われないので注意してください。また、移動させること自身をやめたい(自動Balancing機能をオフにする)場合はmongosのコンソールから以下のコマンドを実行します。
> use config
> db.settings.update( { _id: "balancer" }, { $set : { stopped: true } } , true )
chunkの移動はマニュアルで行うことが出来ますので printShardingSizes() で各shardのサイズ情報を参照にして行うようにしてください。またマニュアルでchunkの分割も行えます。
http://www.mongodb.org/display/DOCS/Moving+Chunks
http://www.mongodb.org/display/DOCS/Splitting+Chunks
余談ですが、このconfigデータベースにはShardingに関する情報が入っています。そしてこのsettingコレクションにはChunkSizeに関する情報も格納されています。ここの値をアップデートすることでchunkSizeの変更も可能であるように見えますが、ここで変更してしまうと様々な問題が生じるらしいのでやめましょう。そして自動ShardingがイヤになったらマニュアルShardingを行えば良いのです。しかしこの設定と以降の管理を行うのはかなり大変です。興味のある人は僕に声をかけてください。
メモリの状況を確認する
完璧なメモリの状況を確認するのは難しいですが、どれくらいのメモリ容量があれば高速にMongoDBが動いてくれるかは以下のコマンドで確認できます。
> db.stats()
{
"collections" : 3,
"objects" : 379970142,
"avgObjSize" : 146.4554114991488,
"dataSize" : 55648683504,
"storageSize" : 61795435008,
"numExtents" : 64,
"indexes" : 1,
"indexSize" : 21354514128,
"fileSize" : 100816388096,
"ok" : 1
}
ここの"indexSize"はインデックスが占める容量になっています。上記の例だと19GBメモリ容量が必要であることがわかります。ただ、メモリがこの容量になくてもMongoDBはもちろん動作します。あくまでこれだけのサイズがあればインデックスは全てメモリ上に載せることができるという指標です。その他にも rs.status() や db.serverStatus() などの情報を参照して種々の状態を監視するようにしてください。(2011年05月19日12時追記)例えば db.sertverStatus() を利用してメモリリークが起きていないかを確認することができます。
> db.serverStatus().mem
{
"bits" : 64,
"resident" : 4074,
"virtual" : 619051,
"supported" : true,
"mapped" : 618515
}
> db.serverStatus().extra_info
{
"note" : "fields vary by platform",
"heap_usage_bytes" : 379296,
"page_faults" : 6322555
}
例えば上の方のコマンドの出力結果で "virtual" と "mapped" の差が実装メモリサイズに比べて大きくなっていればメモリリークの可能性がありますので、より詳細な情報を確認しにいかなければなりません。上記の例では問題なさそうですね。
まとめ
上記のように、MongoDBの挙動を理解して、それに対する対策を適切に行うことによって生じる多くの問題には対応することができます。まだ日本語の情報が整備できていなくて申し訳ないですが、海外ドキュメントや本やブログを細かく読めばいろいろな気づきがあります。僕に聞いてくれればいつでもお答えしますので気軽に質問してください。
といっても、仕様的に解決不可能な問題もたくさんあります。しかしそれらの問題は開発元の10genの人たちが将来的に解決してくれると信じていますし、それを補うツールを自分で作れば良いことです。全ての役割をMongoDBが担ってくれるという期待はせずに、MongoDBが得意な機能だけを使うようにして、MongoDBが苦手な部分はあえて他のツールを使うようにしてください。繰り返しますが、MongoDBは多機能ですが高性能では無いです、様々なトレードオフがあります。
最後に問題定義をして頂いた@kuwa_tw氏、どうもありがとうございました。いつしか毎月開催しているMongoDB勉強会で発表されるのを心待ちにしています。
参考資料
文章中で記載した図は次の3つのスライドからの抜粋になります。
Mongo sharding
View more presentations from Takahiro Inoue
↑Shardingを仕組みから理解したい方、Sharding環境で起こりうる問題について知っておきたい方へ↑
MongoDBで作るソーシャルデータ新解析基盤
View more presentations from Takahiro Inoue
↑Manual ShardingやSlave MapReduceを駆使して解析したい方へ↑
MongoTokyo:10gen エンジニア講演時に行われたQ & A メモ
03月01日(火)に開催されたMongoDB Conference (通称 #mongotokyo) は盛会の内に終了することができました。詳細なレポートは後日アップしていきます。今回はカンファレンスにおいて10genの方々の発表時の質問タイムに議論された内容についてのメモを公開します。
このメモは#mongotokyoに通訳スタッフとして参加していただいた @benhumphreys さんからいただいたものを少し修正したものです。本当にありがとうございます。あくまでメモですので、文章としてきちんと書いていませんので、そこはご了承下さい。
Q) Complex transactionsは実現しますか?
普通は1つのドキュメントに対するtransactionだけサポートしています。
リレーショナルデーターベースのような複数のドキュメントに対するtransactionは
現在のところサポートしていません。ただし将来的には複数ドキュメントtransactionを
サポートする可能性はあります。
Q) 4MB/16MB以下のバイナリーデータはDBに入れても良いでしょうか?
DBにJPGアバターを入れたりする人はいます。
v1.8前のドキュメント当たりの最大サイズは4MBですが、v1.8後は16MBに拡張されます。
しかしまだv1.8に対応してないドライバーは依然として4MBの制限が残ります。
また、インデックスを作成していれば重いバイナリーデータであっても検索時間に影響がありません。
Q) 現在MongoDBを利用しているサービスの中で最大の運用規模はどれくらいでしょうか?
数TBと数Nodeのデータ規模での運用があります。ただし、数千台のサーバーによる
運用事例はあまりありません。MongoDBはCPUをあまり使わないので。
普通の4コアで20,000-40,000 transactions/sec、70% read, 30% write
なので1日に数億オペレーションは可能です。
Q) ロックについて。どのようなコマンドに対してMongoDBはブロックされますか?
現在グローバルロックはあります。DBは編集時にロックされます。
しかし編集における時間は早いので、10−15%の時間しかロックされていません。
MongoStatのツールはこれを見るために役に立ちます。
今はデータを読むコマンドをロックしないように、グローバルロックをなくすように
MongoDBをアップデートしてます。いつかグローバルロックをないようにしたいです。
Q) リレーショナルデーターベースの世界から来るとジョインなしの世界に慣れるのは難しい。ドキュメントIDでジョインみたいなリンクは可能ですが、リンクはプログラミング言語で手動で書かないといけません。将来にこれを自動でできるようになりますか?またlazy loadingとかも実現しないでしょうか?
そうするつもりはありません。今のドライバはそれをサポートしていません。けれどもドライバ上のマッパーがあります。例えばRubyではMongoidとMongoMapperがあり、オブジェクト指向インターフェースを備えています。
Q) Indices。いつインデックスを作れますか?リアルタイムで?production serverで?
2つのオプションがあります。DBをオフラインにして、ブロックするリアルタイムインデックス構築と、オンラインのままで、低いpriorityでのインデックス構築。後者はそれなりに時間がかかります。比較として、インデックスを作る時間はリレーショナルデーターベースと同じぐらいです。しかしNoSQLのDBは大体非常に大きいので時間が結構かかります。