A/Bテストの数理 - 第3回:テストの基本的概念と結果の解釈方法について -
スケジュール
- 第1回 [読み物]:『人間の感覚のみでテスト結果を判定する事の難しさについて』:人間の感覚のみでは正しくテストの判定を行うのは困難である事を説明し,テストになぜ統計的手法が必要かを感じてもらう。
- 第2回 [読み物]:『「何をテストすべきか」意義のある仮説を立てるためのヒント』:何をテストするか,つまり改善可能性のある効果的な仮説を見いだす事は,テストの実施方法うんぬんより本質的な問題である(かつ非常に難しい)。意義のある仮説を立てるためのヒントをいくつか考える。
- 第3回 [数学]:『テストの基本的概念と結果の解釈方法について』:テストの基本的な数学的概念を説明し,またテスト結果をどのように解釈するのかを説明する。
- 第3回補足 [数学]:『仮説検定の概念を改めて考える』:テストの概念をもう少し丁寧に説明する。
- 第4回 [数学]:『実分野における9個のテストパターンについて』その1,その2:オンラインゲーム解析とキャンペーン事例に見る,テストにおける統計量の計算について説明する。
- 第5回 [数学]:『実際にテストを体感する』:いくつかのテスト事例に対し,サンプルデータを提供し実際に統計量の算出を行ってもらう。新シリーズ:「Treasure Data Analytics」の枠組み内で紹介することになりました。
(※ [読み物] は数学知識を前提としない内容で [数学] は数学知識をある程度前提としたおはなし。)
はじめに
第3回ではテストの概念および解釈の方法について説明する。はじめに統計学を強力にサポートする確率論の「大数の弱法則」「中心極限定理」を紹介する。次に背理法に基づくテストの概念を紹介する。
Ⅰ. 統計学の基本スタンスについて
第1回のコラムの続きから始めよう。コラムでは「僕たちは神ではないので答え(真の分布)を知ることはできない。よってその答えに対するヒント(サンプル)から答えを推定することしかできない。」と書いた。(「サンプル」は以後「標本」と呼ぶ。)
僕たちが手元に得られるデータというのは,たいていの場合が全体(母集団)の中の一部(標本)である事が多い。例えば労働調査データでは国民全員のデータでは無く,その中の10万人を独立ランダムにピックアップしたものである。
また,母集団の中からどのようなルール(分布)に従って標本が得られるのかもわからないことが多い。例えば(必ずしも平等でない)コイン投げでは,その母集団は {表, 裏} であることは知っていても表がどれくらいの確率で現れるのかはわからない。
世の中の多くの事象というのはこのように母集団や分布といったそれの本質的な部分を知ることはできず,そこから抽出される一部の標本の持つ(統計量と呼ばれる)情報からそれらを類推しないといけない。
統計学(特に推測統計学と呼ばれるが,ここでは統計と呼ぶことにする)というのは,得られている標本の統計量(標本平均や標本分散)をもとに全体(母集団)や真の分布をテスト(検定)したり推定したりする学問領域である。
Ⅱ. 現実と神の世界を結びつける架け橋:確率論
統計は,現在手元に得られている標本から理論上の真の分布や母集団の情報(誰も知り得ない言わば神の世界)を想像しようとするが,そのためには「現実」と「理論」を結びつけるための何かしらのサポートが不可欠である。この大きな隔たりを極限の世界において華麗に結びつけてくれるのが「大数の弱法則」と「中心極限定理」と呼ばれる,確率論より導かれる性質である。
が,平均
,分散
の独立同一な確率変数列であるとする。今,
と置いたとき,任意の ε > 0 に対して,
が成立する。
大数の弱法則を大まかに言えば,標本数 n を十分に大きくしていけばその標本平均は定数 μ(真の平均)に限りなく近づいていくということを表している。コイン投げの文脈では,試行回数が多ければ多いほど実験で表の出る確率は,真の確率,つまり真のコインの姿をより鮮明に浮かび上がらせる事ができることを示している。
期待値 μ, 分散 の独立同分布の確率変数列
の独立同分布の確率変数列  に対し、
に対し、
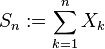
とすると、の標準化統計量
は平均 0, 分散 1 の正規分布 N(0, 1) に分布収束する:
 。
。
中心極限定理を大まかに言えば,標本数 n が十分に大きい状況では標本平均  の分布は近似的に平均
の分布は近似的に平均  , 分散
, 分散  の正規分布
の正規分布  に従う事を述べている。(また,
に従う事を述べている。(また, の分布は近似的に平均
の分布は近似的に平均  , 分散
, 分散  の正規分布
の正規分布  に従うとも言える。)
に従うとも言える。)
ではコイン投げを例に,大数の弱法則と中心極限定理の持たらす意味を考えてみることにしよう。今,平等なコインのコイン投げにおいて表の出る確率を実験によって求めてみる事にする。
※ コイン投げでは,i 回目のコイン投げにおいて表が出たときに1, 裏が出たときに0を取るような確率変数 を仮定すると,独立な変数列
の和
は表の出る回数を表していることになり,これを標本数 n で割った平均
は表が出る確率を表している事になる。この時
をベルヌーイ確率変数とよび,和
の分布は二項分布に従う。
大数の弱法則が意味するところは,コインを投げる回数を増やしていけば行くほど,実験から求めた表の出る確率は真の確率 1/2 に近づくことを示している。コインを n = 1,2,…,1000回独立に投げた場合の表の出る確率をグラフにしてみると,

のようになり,確かに n が大きくにつれて確率 1/2 に近くなっていく。Rにおけるサンプルコードはこちら。
標本数(試行回数) n を一定の値に固定し,毎回コインの表が出ると1, 裏が出ると 0 を標本として取る事にする。ここでは標本平均では無く標本の和,つまり表の出る回数 s を求める動作を 1 セットとして,これを数セット繰り返しヒストグラムを描くことで表の出る回数 s の分布を見てみることにする。下図は左から標本数を n = 10, 20, 1000としたときの分布を表している。標本数が大きいほど,表の出る回数の分布はこの定理より導かれる平均 n*0.5,分散 n*0.5*0.5 の正規分布を良く近似していることがわかる。(ここでセット回数は関心の中心では無い。ヒストグラムの様子を良く表すために n に応じて回数を増やしている)

また,パラメータ σ = 100 の指数分布においては,標本数 n が大きくなるほど,標本平均の分布がよく正規分布を近似している事がよくわかる。

Rでのサンプルコードはこちら。
標準正規分布
標準正規分布は平均 0, 分散 1の正規分布である。この確率密度関数のグラフは以下の図様に表される。縦軸は出やすさの度合い,横軸の値は標本値(標準正規分布における横軸の値をz-valueと呼ばれる。)を表している。縦軸が最大となる標本値はその平均 0 に一致し,そこを頂とする山を形成している。これは標準分布に従った標本を抽出していく場合には,平均値 0 周りを中心に多くの標本値が得られることを意味している。100個の標本値の様子をRで実験してみよう。
table関数によって頻度集計を行うと,ほとんどの標本値が区間 [-2, 2] 内に落ちていることがわかる。実際,95% の標本値が区間 [-1.96,1.96] に落ちることになる。逆に言えば標本値が ±1.96 より離れた標本が得られる確率は両側合わせてたった 5%でしかない。もしあなたがちょうど1回の標本を抽出してみたときに,±1.96 より離れた標本が得られたならば,そのあまりにも希少な出来事に目を疑うことだろう。

Ⅲ. テストの概念について
さて,テストの概念について説明できる準備が整った。ここまででわかっている事実を改めて並べて見よう。(以降で扱う標本は,独立かつ同一な分布から得られていると仮定する。)
- [大数の弱法則] 標本数が十分大きければ標本平均は真の平均に近づいていく。必要ならば真の平均の代替としてこの標本平均を用いて計算を行う事が可能である。
- [中心極限定理] 標本数が十分大きければ元の標本が従う分布が何であっても,標本平均の分布は近似的に正規分布 N(μ, σ^2/n) に従う。さらに標準化と呼ばれる変換を施すことによって得られる統計量 T は標準正規分布 N(0,1) に従う。
- [稀なケース] 標準正規分布においてz-valueが区間 [-1.96, 1.96] 内に収まらない確率は 5% でしかない。(ここで 2. における統計量 T と3. における z-value は同じである。)
もし実験から得た標本から求める統計量 T が計算可能ならば,Tは標準正規分布からの1つの標本であると考えることができる。
定義
「テスト(仮説検定:Hypothesis Testing または有意性検定:Significance Test)とは,母集団または真の分布について設定した仮説の妥当性の判断を,標本を元に計算する統計量を元に一定の確率水準で判定する事である。」
概念
A/Bテストの同型問題であるコイン投げの例では「コインAとコインBの表の出る確率は異なるはずだ」とういう仮説の下でテストを行う。今コインAの表の出る確率を p_a, コインBのそれを p_b とすれば,この仮説は数学的表現として「p_a ≠ p_b である」と表すことができる。しかし実際に設定する仮説は,その対となる「p_a = p_bである」の方になるので注意が必要である。(「p_a = p_bである」という仮説を帰無仮説,これに対立する「p_a ≠ p_bである」という仮説は対立仮説と呼ばれる。 )
これには以下の様な理由がある。(主に最初の方が重要)
テストは棄却を目的とした帰無仮説「p_a = p_bである」の元に検証が行われる。もしこの仮説が妥当では無い(完全否定とは意味合いが異なる)と判断できる場合は帰無仮説を棄却し,対立仮説「p_a ≠ p_bである」の方をより妥当として採択する。
テストでは「否定」という言葉は使わずに「棄却」という言葉を使用する。また帰無仮説の「帰無」とは「棄却することを前提に設定されているので,無に帰す」という意味合いが込められている。
帰無仮説を棄却するということの意味
(今後は区間 [-1.96,1.96] を「採択域」,採択域の外側を「棄却域」と呼ぶことにする。この言葉の意味はすぐに理解できるだろう。)
ではどのようにして帰無仮説を棄却するのだろうか?ここで標本分布の話を思い出して欲しい。帰無仮説の元では統計量 T は標準正規分布に従うが,その値が棄却域に入っているならばこのテストにおいては非常に稀な値を手にしてしまったことになる。
もし僕たちが真の分布を知っている神の立場であれば,この場合でも「稀なケースだったね」という話で済むだろうが,何せ僕たちは(仮定はおいているものの)真の分布を知らない。そのような立場からこの状況を判断するならば,「稀なケース」と考えるよりも「そもそも帰無仮説が正しくなかったのでは無いか」と考える方が妥当の様に思われる。
その考えのもと,T が棄却域に落ちるケースでは帰無仮説を棄却し,例えば「有意な差があると言える」と判断する。「有意」という言葉には「起こる確率が小さい場合には,それはめったに起こらないのでもしそれが起こったとすれば,それは偶然ではなく何か明白な意味が有ると考える方が妥当である」という意味合いが込められている。
ただ状況によっては棄却するか否かの厳しさ,つまり「妥当性の天秤」が異なってくることに注意が必要である。帰無仮説の元で稀なケースを観測する確率を α (ここではずっと α = 0.05 = 5%と置いてきた) とし,これを有意水準と呼ぶ。この有意水準を調整することによってこの妥当性の天秤を調整するのである。一般的に有意水準 α は 0.05 か 0.01 に設定される。後者はより起こりにくい確率を定義しているので,前者よりも帰無仮説を棄却しにくくなりより厳しいテストとなる。有意水準 0.01 の元では採択域は [-2.58, 2.58] と広くなるからだ。
第一種の誤り・第二種の誤り
ただ,本当に稀なケースに遭遇していた可能性もありうる。帰無仮説を誤って棄却してしまう(これを第一種の誤りと呼ぶ)可能性だ。
テストにおいて最終的に導かれる判断には第一種の誤りの可能性を常に含んでいるために,「有意な〜」や「〜であると言える」という控えめな表現を用いる。逆に採択域に収まるケースでは,帰無仮説を棄却することはできないので「このテストからは何もわからない」という判定をする。ここで,”帰無仮説を採択する”という判定を行い,「〜は同じであると言える」などと言ってはいけない。
∵ テストにおいては先ほど紹介した第一種の誤りの他に,第二種の誤りの可能性も内在している。第一種とは逆で,「偽である帰無仮説を採択してしまう誤り」である。第一種ではその誤りの確率は有意水準に等しく,故に制御可能な誤りである。一方,第二種の誤りの方は制御不可能な誤りであり,その確率は未知である。故に安易に帰無仮説を採択する行為は,確率未知の第二種の誤りを容認してしまうことになるので安易に帰無仮説を採択することはできない,故に「何も言えない」という判定にするのである。
問:『今年,新型かもしれないインフルエンザ  が流行の兆しを見せている。もし過去に類を見ないタイプであればすぐに新薬を開発して流行を食い止めなければ大変な事になる。そこで, が本当に新型かどうかを確認するために,患者の症状および血液検査の結果を,過去の似通ったインフルエンザ
が流行の兆しを見せている。もし過去に類を見ないタイプであればすぐに新薬を開発して流行を食い止めなければ大変な事になる。そこで, が本当に新型かどうかを確認するために,患者の症状および血液検査の結果を,過去の似通ったインフルエンザ  が流行した際に取っていた結果と比較し,結果に差があるかどうかをテストすることにした。帰無仮説を「インフルエンザ と は同じである」とした時,第一種の誤りおよび第二種の誤りが何であるかを指摘し,それがもたらす影響を考え,どちらが重大な過ちであるかを考えよ。』
が流行した際に取っていた結果と比較し,結果に差があるかどうかをテストすることにした。帰無仮説を「インフルエンザ と は同じである」とした時,第一種の誤りおよび第二種の誤りが何であるかを指摘し,それがもたらす影響を考え,どちらが重大な過ちであるかを考えよ。』
答:
- 第一種の誤り:
- 第二種の誤り:
Ⅳ. A/Bテストにおける統計量の計算方法について
(※ 統計量の計算とそれの従う分布について,興味の無い方は種々の公式だけ覚えて置けば良いので読み飛ばしてもらっても構わない。)
A/Bテストの同型問題のコイン投げで考える。コインAを n_a 回投げて表の出た回数を y_a,コインBを投げて表の出た回数を y_b と置き,ここでは標本数 n_a, n_b が十分大きいとする。また,それぞれの標本平均を  および
および  と置く。帰無仮説を「p_a = p_b (= p)である」とおく。これは2つの分布の差「p_a - p_b が 0 である」とも書ける。ところで正規分布には以下の様な良好な性質を持っている。
と置く。帰無仮説を「p_a = p_b (= p)である」とおく。これは2つの分布の差「p_a - p_b が 0 である」とも書ける。ところで正規分布には以下の様な良好な性質を持っている。
に従う。帰無仮説の元で共通の確率 p を標本推定値
で置き換えることにすると,標準化した統計量 T は
となり,この時 T は近似的に標準正規分布に従う。
サンプル数とサンプル数の偏りの影響
第1回では,「テストの判定が(人間の感覚的に)標本数の大きさや,標本数で偏りで信念が揺らぐ」傾向にあるという事に触れた。これは先ほど求めた統計量 T が標本数 n_a および n_b の値に依存していることより正しくそれが言える。今回のA/Bテストで導かれた統計量は n_a や n_b が大きくなれば分母が小さくなり,統計量 T としては値が大きくなる傾向にある。これは区間 [-1.96, 1.96] からどんどん遠ざかっていく事を意味し,「とっても稀なケース」としてより確信度高く帰無仮説を棄却できる。
p-値
ところで,この「確信度」というのは「p-値」と呼ばれており,帰無仮説の下で実際にデータから計算された統計量よりも極端な(大きな)統計量が観測される確率である。標準正規分布に従う統計量が T=1.96 の時,有意水準 0.05 の元では p-値は0.025である(両側を併せると有意水準に一致する)。p-値が小さければ小さいほどより稀なケースが起きていることになり,故に帰無仮説が間違っていると考えることの確信度が高まる。p-値は帰無仮説を棄却する事の確信度,というあいまいな感覚値を数値化した有用な指標であると言える。
Ⅴ. まとめおよびその他のテストに関して
ここではA/Bテストの例しか取り上げなかったが,テストは様々な種類がある。それによって計算する統計量 T と T に従う分布は異なってくる。今までは標準正規分布に従う統計量を用いてきたが,その他にも t 分布・F 分布・χ^2 分布に従う統計量が存在する。それらはどれも出発点は中心極限定理と標準正規分布にある。ただサンプル数の大小,または分散が既知か未知かによって計算することのできないパラメータが存在するので,それを四則演算によって巧みに打ち消すようにして作った統計量が t 分布や F 分布に従うのだ。ただし,基本的にはどのテストにおいても,その概念は変わることは無い:
- 大数の弱法則および中心極限定理がテストを強力にサポートする。
- 棄却を目的として,帰無仮説をこしらえる。
- 帰無仮説の下,標本からある分布(正規分布・t分布・F分布・χ^2分布など)に従う統計量 T を求める。
- 統計量 T がその分布の元で稀なケースかどうかをチェックする。(p-値はどれ位稀なケースか、言い換えればどれ位の確信度を持って帰無仮説を棄却できるかを計るための、あらゆる統計量において有用な指標である。)
- 稀なケースであり,帰無仮説を疑う方が妥当であると判断できる場合は帰無仮説を棄却し、対立仮説を採択する。そうでないなら何もわからないと判断する。
- あらゆるテストは誤りの可能性を排除できない。また,第一種の誤り確率は有意水準に等しく制御可能であるが,第二種の誤りは制御不可能である。
興味を持たれた方は色々なパターンを調べて見て欲しい。また,第4回では他の様々なテストが事例とともに登場する。